Текст и строки
Язык программирования Perl, в первую очередь, получил широкую известность как средство обработки текстовой информации - удобное, быстрое, мощное, гибкое. Ларри Уолл создал Perl, чтобы облегчить свою жизнь, когда ему, молодому системному администратору, пришлось заниматься обработкой больших объемов данных, преимущественно текстовых. Удобство работы с текстом заложено практически во всех языковых конструкциях: например, строковый контекст включает автоматическое преобразование чисел и ключей хэша к строкам. В систему программирования Perl встроены необходимые функции для работы с символьной информацией. Наверное, самое мощное средство работы с текстовой информацией - обработка регулярных выражений - эффективно реализована в ядре Perl. Дополнительные средства обработки текста реализованы в стандартных библиотеках. Еще больше функций и классов для работы с текстовыми данными можно найти в модулях из репозитория CPAN.
Текстовая информация хранится в Perl-программе в скалярных переменных. Поскольку Perl не накладывает искусственных ограничений на использование ресурсов компьютера, обычная практика в программах на Perl - считывание всего текста из файла вместе с разделителями строк в одну скалярную переменную, чтобы затем эффективно обработать его. Поэтому в Perl переменные, содержащие символьные данные, называют "строковыми" лишь для краткости, чтобы не говорить "скалярная переменная, содержащая строковое значение".
Строковые литералы
Уже известные из лекции 2 строковые литералы, заключаемые в апострофы и двойные кавычки, могут записываться в альтернативной форме:
'строка в апострофах' или q(строка в апострофах)
"строка в кавычках" или qq(строка в кавычках)
Подобно литеральному списку слов qw(), упомянутому в лекции лекции 5, строковые литералы в этом формате могут ограничиваться разными скобками и практически любыми парными символами: (), {}, [] , <>, //, \\, !! и так далее. Конечно, применение в качестве ограничителей строк таких символов, как &&, ||, %%, ##, '' или $$, допустимо, но не рекомендуется, поскольку может ввести в заблуждение читателя программы. Правила интерполяции действуют и на эту форму записи строковых литералов.
В Perl есть особенные строки, очень похожие на литералы: это строки, заключенные в обратные апострофы (back-quotes, backticks) ``, для которых также есть эквивалентная запись в виде qx(). Особенность таких строк заключается в том, что их содержимое рассматривается как синхронный вызов внешней программы или команды операционной системы, которая выполняется во время работы Perl-программы. Фактически это операция выполнения программы. Результат выполнения указанной внешней программы становится значением конструкции qx(). При этом в ней производится интерполяция. Так, например, в среде MS Windows или Linux с помощью команды dir можно получить список MP3-файлов и поместить его в переменную:
$music_files = `dir *.mp3`; # или qx(dir .\*.mp3)
Таким же образом можно легко воспользоваться услугами любой другой программы. Недаром Perl часто называют "склеивающим языком" (glue language): с помощью Perl-программы можно обращаться к имеющимся программам, получать результат их выполнения и обрабатывать его по усмотрению программиста. Так, упомянутый в лекции 1 прием использования программ-фильтров получил в Perl дальнейшее развитие. Другие примеры использования операции выполнения программы приведены в лекции 16.
Встречается еще один тип строковых литералов, называемых V-строки ("V-strings" - строки версий), хотя он считается устаревшим и может не поддерживаться в будущем.
v1.20.300.4000 # то же, что "\x{1}\x{14}\x{12c}\x{fa0}"
v9786 # "смайлик" ? (символ Unicode \x{263A})
v79.107.33 # строка 'Ok!'
79.107.33 # в литерале с несколькими точками можно без "v"
V-строки полезны для сравнения "номеров" версий с помощью операций строкового сравнения, например:
$version = v5.8.7;
print "Версия подходит\n" if $version ge v5.8.0;
V-строки иногда также применяются для записи сетевых адресов IPv4, например: v127.0.0.1.
Преобразующие escape-последовательности
Кроме escape-последовательностей, описанных в лекции 2, в Perl есть особые управляющие последовательности, предназначенные для преобразования символов в строковом литерале. Они приведены в таблице 7.1. С их помощью преобразуется либо один символ, следующий за escape-последовательностью, либо несколько символов до отменяющей последовательности.
Таблица 7.1. Преобразующие escape-последовательности
| Управляющая последовательность |
Мнемоника символа |
Преобразование |
| \u |
Upper case |
преобразовать следующий символ к верхнему регистру |
| \l |
Lower case |
преобразовать следующий символ к нижнему регистру |
| \U |
Upper case |
преобразовать символы до \E к верхнему регистру |
| \L |
Lower case |
преобразовать символы до \E к нижнему регистру |
| \Q |
Quote |
отменить специальное значение символов вплоть до \E |
| \E |
End |
завершить действие \U или \L |
Применение этих преобразующих escape-последовательностей можно проиллюстрировать такими примерами:
use locale; # для правильной обработки кириллицы
$name = 'мария'; # будем преобразовывать значение переменной
print "\u$name"; # будет выведено: Мария
print "\U$name\E"; # будет выведено: МАРИЯ
print "\Q$name\E"; # будет выведено: \м\а\р\и\я
Аналогичного результата можно достигнуть при использовании некоторых строковых функций, о которых пойдет речь далее в этой лекции.
Встроенные документы
Еще одним видом непосредственной записи в программе текстовой информации являются так называемые встроенные документы (here-documents). Эта конструкция, заимствованная из командного языка Unix, представляет из себя встроенный в программу произвольный текст. Встроенный документ начинается символами <<, за которыми без пробелов указывается ограничитель, отмечающий конец документа. Все строки, начиная со следующей, рассматриваются как содержимое этого документа до тех пор, пока не встретится строка, состоящая только из указанного ограничителя. Обозначающий конец встроенного документа ограничитель должен записываться на отдельной строке с самого ее начала.
$here_document = <<END_OF_DOC;
Здесь располагается текст встроенного документа,
ограничитель которого записывается с начала
на отдельной строке.
END_OF_DOC
Если желательно записывать ограничитель с пробелами, то его нужно заключить в кавычки, а если он записан кириллицей, то нужно прагмой use locale включить учет национальных установок:
use locale;
$here_document = <<'КОНЕЦ ДОКУМЕНТА';
ЭТО НЕ КОНЕЦ ДОКУМЕНТА
КОНЕЦ ДОКУМЕНТА
Во встроенных документах производится интерполяция переменных, если только ограничитель here-документа не заключен в одинарные апострофы. Поэтому встроенные документы часто применяются для комбинирования предварительно отформатированного текста со значениями переменных, как это сделано в следующем примере:
$here_document = <<"END_OF_DOCUMENT"; # присваивание строке
Уважаемый $guests[$n]!
Приглашаем Вас на презентацию книги "$title",
которая состоится $date в $time.
Оргкомитет.
END_OF_DOCUMENT
print $here_document, '-' x 65, "\n";
Например, с помощью here-документа легко и удобно программно создать HTML-страницу, вставляя в нее нужную информацию:
$web_page = <<HTML; # поместить here-документ в переменную
<!DOCTYPE html
PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta http-equiv="content-type"
content="text/html; charset=$encoding"/>
<meta name="author" content="$author"/>
<title>$title</title>
</head>
<body>
<h3 style="text-align: center;">$header</h3>
<div align="justify">$article{$number}</div>
<p><a href="$hyperlink">Вернуться к разделу $topic</a><p>
<hr/><small>Copyright © $year, $author.</small>
</body>
</html>
HTML
Это один из способов динамического создания на web-сервере гипертекстовых страниц в ответ на запрос информации, например, хранимой в базе данных.
Функции для работы со строками
В предыдущих лекциях уже упоминались функции, обрабатывающие символьную информацию:
- chomp(), удаляющая в конце строки символ-разделитель записей;
- chop(), отсекающая любой последний символ строки;
- join(), объединяющая элементы массива в одну строку;
- split(), разделяющая строку на список подстрок.
В этой лекции мы познакомимся с другими встроенными функциями для работы с текстом. Хотя в приведенных далее примерах аргументы функций заключены в круглые скобки, использование скобок при вызове встроенных функций необязательно, если не возникает неоднозначности определения аргументов функции.
Часто требуется выяснить, содержит ли строка ту или иную подстроку. Функция index() выполняет поиск подстроки в строке, начиная с определенного смещения, и возвращает номер позиции найденной подстроки. Функция rindex() ищет подстроку от конца строки и возвращает позицию последней подстроки в строке перед указанным смещением. Смещение можно не указывать, тогда поиск производится во всей строке. Номера позиций подстроки и смещения начинаются с нуля. Если подстрока не найдена, возвращается -1. Например:
$pos = index($string, $sub_string, $offset); # с начала
$last_pos = rindex($string, $sub_string, $offset); # с конца
print "есть правда!" if(index($life, 'правда') != -1);
В следующей главе будет рассказано о регулярных выражениях, с помощью которых можно гибко управлять поиском подстроки, задавая шаблоны приблизительного соответствия и расположение подстрок относительно друг друга.
Определение длины текста - также весьма распространенная операция. Функция length() возвращает длину в символах значения строки или выражения, возвращающего строку или преобразованного к строке:
$string_length = length($string); # строка в переменной
$n *= 2 until(length($n)>10); # длина числа
print 'Текст слишком длинный' if length($s1 . $s2) > $limit;
Функция substr(), выполняющая выделение подстроки из строки, всегда была очень популярной в большинстве языков (кроме Perl, в котором это действие чаще выполняется с помощью регулярных выражений). Она копирует из строки подстроку заданной длины, начиная с указанного смещения. Если смещение отрицательное, то оно отсчитывается от конца строки. Если длина подстроки не задана, то копируется строка после смещения до самого конца:
$sub = substr($string, # копировать в $sub из $string,
$offset, # отступив $offset символов,
$length); # подстроку длиной $length
$e = substr($s, rindex($s,'.')); # от последней '.' до конца
$last_char = substr($string, -1, 1); # последний символ
Необычность функции substr() в Perl состоит в том, что она может применяться для изменения строки, относясь к группе так называемых левосторонних функций, которые могут употребляется в левой части операции присваивания. В этом случае значение, стоящее в правой части присваивания, заменяет подстроку, которая извлекается из строки функцией substr(), стоящей слева от знака присваивания. Например, вот так можно подстроку длиной в два символа, начинающуюся с символа с индексом 5, заменить новой строкой:
$string = 'Perl 5 нравится программистам.';
$new_string = '6 тоже по';
substr($string, 5, 2) = $new_string;
# в $string будет: 'Perl 6 тоже понравится программистам.'
Подобным же образом можно удалить последние 5 символов строки, заменив их пустой строкой:
substr($string, -5) = ''; # удалить последние 5 символов
Сочетая уже известные функции, можно выполнять разные манипуляции с текстовой информацией. Например, чтобы переставить слова в строке, можно воспользоваться функциями split(), reverse() и join() в списочном контексте:
$reverse_words = join(' ', reverse(split(' ', $text)));
В Perl есть набор функций для преобразования букв из заглавных в строчные и наоборот. Для правильного преобразования русских букв нужно включить поддержку национальных установок операционной системы с помощью прагмы use locale. Преобразовать текст к нижнему регистру (lower case) можно с помощью функции lc(), которая возвращает значение текстового выражения, преобразованное к строчным буквам:
use locale; # учитывать национальные установки
$lower_case = lc($text); # преобразовать к маленьким буквам
Функция lcfirst() возвращает значение строкового выражения, в котором только первый символ преобразован к нижнему регистру, например:
$first_char_lower = lcfirst($text); # 'Perl' станет 'perl'
К верхнему регистру (upper case) преобразовать текст можно с помощью функции uc(), которая возвращает значение символьного выражения, преобразованное к заглавным буквам.
use locale;
$upper_case = uc($text); # преобразовать к большим буквам
Функция ucfirst() возвращает значение строкового выражения, в котором только первый символ преобразован к верхнему регистру. Так, например, можно записать имя собственное с заглавной буквы:
$capitalized = ucfirst($name); # 'ларри' станет 'Ларри'
Встроенная функция crypt() выполняет шифрование строки, переданной ей в качестве аргумента, используя второй аргумент в качестве "затравки" (salt) для шифрования:
# незашифрованная строка из $plain шифруется в $crypted
$crypted = crypt($plain, $salt);
Эта функция не имеет парной расшифровывающей функции и чаще всего используется для сравнения открытого текста с существующей зашифрованной строкой, как это делается в следующем примере:
if (crypt($plain, $salt) eq $crypted) {
# открытый текст совпал с зашифрованным
}
Функция quotemeta() находит в символьном выражении метасимволы (о которых пойдет речь в следующей лекции) или escape-последовательности и возвращает строку, где у всех специальных символов отменено их особое значение: для этого перед каждым из них ставится символ обратной косой черты '\'.
$string_with_meta = '\n \032 \x00 text \t \v "';
$quoted = quotemeta($string_with_meta);
# в $quoted будет '\\n\ \\032\ \\x00\ text\ \\t\ \\v\ \"'
В Perl имеется несколько функций преобразования строкового представления числа в числовое значение. Функция hex() возвращает десятичное значение выражения, представленного как шестнадцатиричное число в виде строки:
$hexadecimal_as_string = '0x2F';
$decimal_number = hex($hexadecimal_as_string); # будет 47
Функция oct() возвращает десятичное значение строкового выражения, представляющего запись восьмеричного числа:
$octal_as_string = '0777';
$decimal_number = oct($octal_as_string); # будет 511
С помощью oct() можно также преобразовать к десятичному значению двоичное или шестнадцатиричное число, записанное в виде строки:
$binary_as_string = '0b011001';
$decimal_number = oct($binary_as_string); # будет 25
$hexadecimal_as_string = '0x19';
$decimal_number = oct($hexadecimal_as_string); # будет 25
Ну а строку, содержащую число в десятичной системе счисления, можно преобразовать к числу, поместив ее в числовой контекст:
$pi_as_string = '3.141592653'; # число Пи в виде строки
$circle_length = 2 * $pi_as_string * $radius;
Функция sprintf() возвращает строку, которая сформирована в соответствии с правилами форматирования, заимствованными из языка C: на основе формата преобразования, заданного первым аргументом, в результирующую строку подставляются отформатированные значения из списка остальных аргументов функции. В общем виде вызов этой функции выглядит так: sprintf(ФОРМАТ, СПИСОК АРГУМЕНТОВ). В формате преобразования располагается любой текст, в котором могут присутствовать указания преобразования. Каждое указание начинается с символа процента (%) и заканчивается символом, определяющим преобразование. Основные преобразования приведены в таблице 7.2.
Таблица 7.2. Преобразования в формате sprintf
| Преобразование |
Синоним |
Результат преобразования |
Мнемоника символа |
| %% |
|
Знак процента |
% |
| %c |
|
Символ с указанным номером в кодовой таблице |
Character |
| %s |
|
Строка |
String |
| %d |
%i |
Целое со знаком в десятичном виде |
Decimal, Integer |
| %u |
|
Целое без знака в десятичном виде |
Unsigned |
| %b |
|
Целое без знака в двоичном виде |
Binary |
| %o |
|
Целое без знака в восьмеричном виде |
Octal |
| %x |
%X |
Целое без знака в шестнадцатеричном виде |
heXadecimal |
| %e |
%E |
Целое с плавающей точкой в научной нотации |
Exponential |
| %f |
%F |
Число с плавающей точкой в виде десятичной дроби |
Float |
| %g |
%G |
Число с плавающей точкой в формате %e или %f |
|
Между знаком процента и символом в указании преобразования можно использовать дополнительные параметры преобразования, основные из которых приведены в таблице 7.3.
Таблица 7.3. Параметры преобразования в формате sprintf
| Параметр |
Выполняемое форматирование |
Пример параметров sprintf() |
Результат форматирования |
| число |
Минимальная ширина поля вывода для результата преобразования; если она не задана или меньше ширины значения, то устанавливается равной ширине выводимого значения |
'<%5s>', 25 |
< 25> |
| .число |
Количество цифр после десятичной точки в дробном числе |
'<%.5f>', 0.25 |
<0.25000> |
| Максимальная ширина поля вывода, до которой усекается длинная строка |
'<%.5s>', '5' x 10 |
<55555> |
| пробел |
Вывод пробела перед положительным числом |
'<% d>', 25 |
'< 25>' |
| + |
Вывод плюса перед положительным числом |
'<%+d>', 25 |
'<+25>' |
| 0 |
Вывод нулей, а не пробелов при выравнивании по правому краю поля |
'<%05s>', 25 |
'<00025>' |
| - |
Выравнивание значения по левому краю поля |
<%-5s>, 25 |
'<25 >' |
| # |
Вывод перед восьмеричным числом 0, перед шестнадцатеричным числом 0x, перед двоичным числом 0b |
'<%#x>',25 |
'<0x19>' |
При выполнении sprintf() к очередному значению из списка аргументов применяется преобразование, результат которого вставляется в форматирующую строку на место указания преобразования. Например, если шаблон форматирования и аргументы функции sprintf() заданы так:
$format = "'%12s' агента <%03d> = '%+-10.2f'";
@list = ('Температура', 7, 36.6);
$formatted_string = sprintf($format, @list);
то после выполнения приведенного предложения в переменной $formatted_string будет содержаться такая отформатированная строка:
' Температура' агента <007> = '+36.60 '
Преобразования в формате этого примера обозначают следующее:
- %12s - преобразовать аргумент в строку (string) и поместить в поле шириной в 12 символов с выравниванием вправо (т. к. ширина поля положительная);
- %03d - преобразовать аргумент в десятичное целое (decimal) и поместить в поле шириной в 3 цифры с ведущими нулями (т. к. ширина поля задана с ведущим нулем) и выравниванием вправо (поскольку ширина положительная);
- %+-10.2f - преобразовать аргумент в дробное число (float) с явным знаком (т.к. указан +) и поместить в поле шириной в 10 цифр, из которых 2 отводятся на дробную часть, с выравниванием влево (поскольку ширина поля отрицательная).
Функция sprintf() часто применяется для округления чисел - например, до трех знаков в дробной части:
$rounded = sprintf("%.3f", 7/3); # в $rounded будет 2.333
Полное описание форматов с самыми разными примерами их употребления можно прочитать в официальной документации:
В дополнение к функции sprintf() имеется функция printf(), которая использует тот же самый формат преобразования, но выводит отформатированный результат в указанный выходной поток.
Функции для работы с символами
Иногда требуется работать не со строками и словами текста, а с его отдельными символами. В Perl есть необходимые средства работы с символами, хотя в нем нет специального типа данных, представляющих один символ, подобно типу char в других языках. Один символ из строки можно скопировать функцией substr($string, $index, 1).
С помощью заимствованных из языка Pascal функций ord() и chr() выполняются преобразования символа (а точнее односимвольной строки) в его ASCII-код и наоборот:
$code = ord($char); # ord('M') вернет число 77
$char = chr($code); # chr(77) вернет строку 'M'
# синоним: $char = sprintf("%c", $code);
Разбить строку на отдельные символы и поместить их в массив можно с помощью уже знакомой функции split() с пустой строкой в качестве разделителя:
@array_of_char = split('', $string);
С помощью списков и нескольких вызовов функции substr() можно поменять в строке местами символы с указанными индексами, например, 1 и 11:
$s = 'кОт видел кИта';
(substr($s, 1, 1), substr($s, 11, 1)) =
(substr($s, 11, 1), substr($s, 1, 1));
# в $s будет 'кИт видел кОта'
Известная по лекции о списках функция reverse() в скалярном контексте возвращает значение текстового выражения, в котором символы переставлены в обратном порядке, например:
$palindrom = 'А РОЗА УПАЛА НА ЛАПУ АЗОРА';
$backwards = reverse($palindrom);
# в $backwards будет 'АРОЗА УПАЛ АН АЛАПУ АЗОР А'
Обрабатывать отдельные байты, в том числе и символы, можно также при помощи функций pack() и unpack(), которые предназначены для преобразования любых данных и будут рассмотрены в лекции, посвященной вводу-выводу.
Поддержка Unicode
В современном мире уже не работает формула "один символ - это один байт". Необходимость представления текстов, одновременно содержащих символы разных естественных языков, привела к появлению ряда стандартов, часто объединяемых под общим названием Unicode и разработанных международным Консорциумом Unicode. Многочисленные национальные символы языков мира кодируются последовательностями из нескольких байтов. Unicode предлагает несколько форм представления символов в виде форматов преобразования Unicode (Unicode Transformation Format, UTF) и наборов символов Unicode (Unicode Character Set, UCS). Стандарты UCS-2 и UCS-4 представляют из себя кодировки фиксированной длины по два и четыре байта. Из кодировок переменной длины самым популярным стал стандарт UTF-8, использующий для кодирования одного символа от одного до шести байт. Начиная с версии 5.6, Perl поддерживает обработку символов в кодировках Unicode. В Perl применяется кодирование символов последовательностями чисел переменной длины на основе представления UTF-8. Есть возможность записывать многобайтовые (multi-byte) символы в виде литералов, а также выполнять ввод-вывод Unicode-символов.
Для записи в исходной программе символов Unicode в представлении UTF-8 нужно включить обработку строк в этом формате прагмой use utf8. После этого многобайтовые символы могут использоваться наравне с однобайтовыми, например, в качестве ключей в хэшах:
use utf8; # включить поддержку UTF-8
$hash{'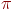 '} = 3.141592653; # пи (код \x{03C0})
print "$hash{''}\n"; # будет выведено: 3.141592653 '} = 3.141592653; # пи (код \x{03C0})
print "$hash{''}\n"; # будет выведено: 3.141592653
Можно даже использовать национальные алфавиты для записи идентификаторов переменных. Например, кириллицу или греческий:
use utf8;
$скаляр = 25; # имя скаляра на русском
$ = $скаляр + 53; # имя скаляра на греческом
print "$скаляр $\n"; # будет выведено: 25 78
@массив = ($, $скаляр); # имя массива на русском
print "@массив\n"; # будет выведено: 78 25 = $скаляр + 53; # имя скаляра на греческом
print "$скаляр $\n"; # будет выведено: 25 78
@массив = ($, $скаляр); # имя массива на русском
print "@массив\n"; # будет выведено: 78 25
Для ввода текста подобной программы понадобится редактор, поддерживающий работу с Unicode. Например, в операционной системе MS Windows это можно сделать с помощью программы Notepad. А в ОС GNU/Linux для редактирования этого текста можно воспользоваться редактором KWrite или Kate. Если такой возможности нет, то символы Unicode можно записывать в программе с помощью escape-последовательностей, о чем было рассказано в лекции 2. Примеры escape-кодов для записи символов Unicode приведены во фрагменте программы далее в этой лекции.
Скалярные значения в Perl имеют специальный "признак utf8" (utf8 flag), который устанавливается, когда значение представлено в UTF-8. В этом случае правильно выполняется обработка многобайтовых символов встроенными функциями chr(), index(), length(), ord(), rindex(), substr(). Это видно на таком примере:
use utf8;
$u = "€500"; # знак евро (escape-код \x{20AC})
print "Длина=", length($u), "\n"; # Длина=4
$u = '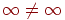 '; # коды \x{221E}, \x{2260}, \x{221E}
print "Бесконечности не равны\n" if $u eq reverse '???'; '; # коды \x{221E}, \x{2260}, \x{221E}
print "Бесконечности не равны\n" if $u eq reverse '???';
Переключить встроенные функции на работу не с символами, а с байтами можно с помощью прагмы use bytes. Снова переключиться на работу функций не с байтами, а с символами можно с помощью прагмы no bytes. Подключив прагмой use Encode стандартный модуль преобразования можно преобразовать обычную строку в строку символов Unicode с помощью функции encode(), возвращающей символьную строку в представлении UTF-8. Обратное преобразование выполняет функция decode():
use Encode;
my $cp1251 = 'Привет!'; # строка в кодировке windows-1251
my $utf8 = encode('utf8', $cp1251); # преобразуется в UTF-8
my $win_ru = decode('utf8', $utf8); # и наоборот
Поддержка наборов символов Unicode в Perl имеет свои особенности, связанные с обеспечением совместимости со старыми байт-ориентированными программами, но эти особенности заслуживают отдельного продолжительного разговора за рамками данного учебного курса.
В этой лекции рассмотрены средства работы с символьной информацией в Perl, достаточные для решения типичных задач обработки текста. Но вся прелесть языка Perl и его мощь открываются только тем, кто освоит регулярные выражения, о которых пойдет речь в следующей лекции.
|

 Посмотреть
порно видео в онлайне »
Посмотреть
порно видео в онлайне »