| Многозадачность Современные операционные системы в том или ином виде поддерживают многозадачность (multitasking) даже на однопроцессорных компьютерах, не говоря уже о многопроцессорных системах. Операционная система (ОС) производит запуск системных и пользовательских программ в виде независимых процессов (process), выделяя для каждого из них отдельный участок оперативной памяти и другие ресурсы. Каждый процесс нумеруется своим уникальным числовым идентификатором процесса (Рrocess Identifier, PID). Специальные модули ядра операционной системы организуют переключение процессора на обслуживание выполняющихся программ, оптимизируя распределение между ними процессорного времени. При этом работающие процессы могут инициировать выполнение других процессов, порождать зависимые подпроцессы (subprocess) в отдельной области памяти или запускать подпроцессы в области памяти основного процесса. Примерами программ, основанных на использовании подпроцессов, могут служить различные серверные программы: почтовые и web-серверы, серверы приложений и баз данных.
Во время выполнения процессы могут взаимодействовать между собой различными способами. Они могут иметь доступ к разделяемой области памяти, организовывать программные каналы (pipe), посылать друг другу сигналы (signal), обмениваться данными через сокеты, совместно использовать файлы и применять другие средства межпроцессного взаимодействия (Inter-Process Communication, IPC). При этом часто один процесс ожидает окончания выполнения каких-либо действий в другом процессе: про такую ситуацию говорят, что процессы выполняются синхронно (synchronous), то есть согласованно. В других случаях требуется, чтобы процессы выполнялись асинхронно (asynchronous), то есть одновременно и независимо друг от друга. В определенный момент процесс может перейти от асинхронного выполнения к синхронному, то есть перейти в ожидание для синхронизации с другим процессом.
Реализация этих механизмов сильно зависит от конкретной операционной системы, поэтому некоторые стандартные средства языка Perl, связанные с управлением процессами, ориентированы на работу в определенном операционном окружении. Кроме того, имеются специализированные Perl-модули для работы с процессами в операционных системах, соответствующих стандарту POSIX, или в ОС MS Windows. Конечно, в этой лекции нам удастся обсудить только основные средства языка Perl, касающиеся обширной темы межпроцессного взаимодействия. Приводимые примеры намеренно сделаны максимально простыми, чтобы продемонстрировать основные подходы к управлению процессами, избегая особенностей, которыми изобилует многозадачное программирование.
Выполнение внешних программ
В Perl имеется операция выполнения программы, которая обозначается обратными апострофами (backticks) или синонимом - конструкцией qx(), упоминавшейся в лекции 7. Она предназначена для получения результатов выполнения внешней программы. Эта операция пытается выполнить любую внешнюю программу, ожидает окончания ее работы и возвращает то, что программа выводит в свой поток стандартного вывода. Например, так в операционных системах Linux или MS Windows можно выполнить команду dir, выводящую список файлов в текущем каталоге:
my $file_list = `dir`; # в скалярном контексте
my @file_list = qx(dir); # в списочном контексте
В зависимости от того, в каком контексте - скалярном или списочном - употребляется операция выполнения программы, результат работы внешней программы рассматривается как одна строка или как список строк.
Выполнить внешнюю программу можно также с помощью функции system, которая организует синхронный запуск программы и возвращает код завершения. Код завершения 0 означает, что команда была выполнена успешно. Приведем пример ее использования в программе, архивирующей файлы с суффиксом .pl в текущем каталоге:
use English; # использовать длинные имена спец. переменных
# в ОС MS Windows архивируем файлы с помощью pkzip
if ($OSNAME =~ m/win/i) {
system "pkzip", "-a", "pearls.zip", "*.pl";
# в ОС GNU/Linux архивируем файлы с помощью tar и gzip
} elsif ($OSNAME =~ m/linux/i) {
system "tar -cv *.pl | gzip > pearls.tar.gz";
}
При вызове с одним строковым аргументом функция system() использует для запуска командный интерпретатор операционной системы так же, как функции exec(), open() и операция qx(). При передаче ей нескольких аргументов она запускает внешнюю программу с помощью системного вызова (обращения к операционной системе). Чтобы обеспечить успешный поиск запускаемой программы, можно добавить каталог, где находится программа, в список путей поиска. Например, таким образом:
{ # временно помещаем каталог с программой в пути поиска
local $ENV{"PATH"} = $path_to_the_program; # каталог
system($program_to_execute); # вызов программы
} # значение $ENV{"PATH"} будет восстановлено
Выполнение внешних программ можно организовать с помощью функции open, если требуется обмениваться данными с этими программами, используя перенаправление потоков ввода-вывода. Для этого функции open() вместо имени файла передается командная строка с именем выполняемой программы и ее аргументами. Если нужно передать поток данных для обработки из Perl-программы в вызываемую программу, то перед командой указывается символ командного конвейера '|'. Как это делается, видно из очень простого примера, в котором случайным образом генерируются числовые пароли, а затем они направляются для сжатия в архив программой gzip:
# открываем выходной поток, направляем его внешней программе
open my $archive, "| gzip > passwords.gz";
for (my $i = 1; $i <= 12; $i++) { # генерируем пароли
printf $archive "%06.0f\n", rand 999999;
}
close $archive; # закрываем выходной поток
Когда нужно принять выходной поток внешней программы для обработки в Perl-программе, то символ конвейера команд '|' ставится в конце командной строки:
# открываем входной поток, полученный от внешней программы
open my $archive, "gzip -d < passwords.gz |";
while (my $line = <$archive>) { # читаем пароли из архива
print $line;
}
close $archive; # закрываем выходной поток
(Используемый в примерах архиватор gzip распространяется свободно, версии для самых разных ОС доступны на сайте http://www.gzip.org.)
Замена текущего процесса
Иногда требуется организовать выполнение программы таким образом: вначале запускается загрузчик, который, в зависимости от условий, заданных в конфигурации программы, запускает вместо себя основную программу. Этот подход можно реализовать с помощью функции exec, которая заменяет работающую программу на указанную. Так можно запускать не только Perl-программы. Этот прием можно проиллюстрировать таким примером:
print "Выполняется загрузчик: $0, PID:$$\n";
# заменить текущую программу на указанную
my $program = $ARGV[0]; # имя программы в 1-м аргументе
print "Запускается программа: $program\n";
exec 'perl', $program or die; # запуск программы
print "Это сообщение никогда не напечатается!\n";
При запуске этого примера с параметром 'proc_executed.pl' будут выведены такие сообщения:
Выполняется загрузчик: proc_exec.pl, PID:652
Запускается программа: proc_executed.pl
Выполняется программа: proc_executed.pl, PID:1872
Параллельное выполнение процессов
Для организации параллельного выполнения процессов в Perl используется функция fork ("разветвить"). В результате ее работы создается копия выполняющегося процесса, которая тоже запускается на выполнение. Для этого в операционных системах семейства Unix происходит обращение к системному вызову fork. В других операционных системах работа функции fork() организуется исполняющей системой Perl. Функция fork() в родительском процессе возвращает PID дочернего процесса, число 0 - в дочернем процессе и неопределенное значение при невозможности запустить параллельный процесс. Это значение проверяется в программе, чтобы организовать выполнение различных действий в процессе-предке и процессе-потомке. Как это делается, показано на следующем схематичном примере (где оба процесса в цикле выводят числа, но с разными задержками):
my $pid = fork(); # 'разветвить' текущий процесс
# fork вернет 0 в потомке и PID потомка в процессе-предке
die "fork не отработал: $!" unless defined $pid;
unless ($pid) { # процесс-потомок
print "Начался потомок PID $$\n";
for (1..3) {
print "Потомок PID $$ работает $_\n";
sleep 2; # 'заснуть' на 2 секунды
}
print "Закончился потомок PID $$\n";
exit;
}
if ($pid) { # процесс-предок
print "Начался предок PID $$\n";
for (1..3) {
print "Предок PID $$ работает $_\n";
sleep 1; # 'заснуть' на 1 секунду
}
# возможно, здесь нужно ждать завершения потомка:
# print "Предок PID $$ ждет завершения $pid\n";
# waitpid $pid, 0;
print "Закончился предок PID $$\n";
}
По сообщениям, выводимым при выполнении этого примера, видно, что родительский и порожденный процессы выполняются параллельно. Для того чтобы организовать в родительском процессе ожидание завершения дочернего процесса, применяется функция waitpid(), которой передается PID процесса-потомка (а также, возможно, дополнительные параметры). По выдаваемым сообщениям сравните два варианта выполнения приведенной выше программы - без ожидания завершения дочернего процесса и с ожиданием завершения процесса-потомка (для этого нужно раскомментарить вызов функции waitpid):
Без ожидания потомка С ожиданием потомка по waitpid()
---------------------------- --------------------------------
Начался потомок PID -1024 Начался потомок PID -1908
Потомок PID -1024 работает 1 Потомок PID -1908 работает 1
Начался предок PID 1504 Начался предок PID 1876
Предок PID 1504 работает 1 Предок PID 1876 работает 1
Предок PID 1504 работает 2 Предок PID 1876 работает 2
Потомок PID -1024 работает 2 Потомок PID -1908 работает 2
Предок PID 1504 работает 3 Предок PID 1876 работает 3
Закончился предок PID 1504 Предок PID 1876 ждет завершения -1908
Потомок PID -1024 работает 3 Потомок PID -1908 работает 3
Закончился потомок PID -1024 Закончился потомок PID -1908
Закончился предок PID 1876
Выполнение всей программы заканчивается, когда заканчивается последний порожденный процесс. Ожидание окончания выполнения всех дочерних процессов можно организовать с помощью функции wait(), которая возвращает PID завершившегося подпроцесса и -1, если все процессы-потомки завершили работу.
Взаимодействие подпроцессов
В Perl есть несколько способов организации взаимодействия процессов при их параллельном выполнении. Один из них - создать программный канал (pipe), который представляет из себя два файловых манипулятора - приемник (reader) и передатчик (writer) - связанных таким образом. что записанные в передатчик данные могут быть прочитаны из приемника. Программный канал создается с помощью функции pipe(), которой передаются имена двух файловых манипуляторов: приемника и источника. Один из вариантов взаимодействия процессов через программный канал показан в следующем примере:
use IO::Handle; # подключаем стандартный модуль
pipe(READER, WRITER); # создаем программный канал
WRITER->autoflush(1); # включаем авто-очистку буфера
if ($pid = fork()) { # процесс-предок получает PID потомка
close READER; # предок не будет читать из канала
print WRITER "Послано предком (PID $$):\n";
for (my $n = 1; $n <= 5; $n++) { # запись в передатчик
print WRITER "$n ";
}
close WRITER; # закрываем канал и
waitpid $pid, 0; # ждем завершения потомка
}
die "fork не отработал: $!" unless defined $pid;
if (!$pid) { # процесс-потомок получает 0
close WRITER; # предок не будет писать в канал
print "Потомок (PID $$) прочитал:\n";
while (my $line = <READER>) { # чтение из приемника
print "$line";
}
close READER; # канал закрывается
exit; # потомок завершает работу
}
Во время выполнения этого примера в стандартный выходной поток будет выведено следующее:
Потомок (PID -2032) прочитал:
Послано предком (PID 372):
1 2 3 4 5
Если нужно организовать передачу данных в обратном направлении, организуется канал, в котором передатчик будет в процессе-потомке, а приемник - в процессе-предке. Так как с помощью программного канала можно передавать данные только в одном направлении, то при необходимости двустороннего обмена данными между процессами создаются два программных канала на передачу в обоих направлениях.
Кроме программных каналов, процессы могут обмениваться информацией и другими способами: через именованные каналы (FIFO) и разделяемые области памяти, если они поддерживаются операционной системой, с помощью сокетов (что будет рассмотрено в следующей лекции) и при помощи сигналов.
Сигналы и их обработка
В операционных системах имеется механизм, который может доставлять процессу уведомление о наступлении какого-либо события. Этот механизм основан на так называемых сигналах. Работа с ними происходит следующим образом. В программе может быть определен обработчик того или иного сигнала, который автоматически вызывается, когда ОС доставляет сигнал процессу. Сигналы могут отправляться операционной системой, или один процесс может с помощью ОС послать сигнал другому. Процесс, получивший сигнал, сам решает, каким образом реагировать на него, - например, он может проигнорировать сигнал. Перечень сигналов, получение которых можно попытаться обработать, находится в специальном хэше с именем %SIG. Поэтому допустимые идентификаторы сигналов можно вывести функцией keys(%SIG). Общеизвестный пример - сигнал прерывания выполнения программы INT, который посылает программе операционная система по нажатию на консоли сочетания клавиш Ctrl+C. Как устанавливать обработчик конкретного сигнала, показано на примере обработки сигнала INT:
# устанавливаем обработчик сигнала INT
$SIG{INT} = \&sig_handler; # ссылка на подпрограмму
# начало основной программы
print "Работаю в поте лица...\n" while (1); # бесконечный цикл
sub sig_handler { # подпрограмма-обработчик сигнала
$SIG{INT} = \&sig_handler; # переустанавливаем обработчик
print "Получен сигнал INT по нажатию Ctrl+C\n";
print "Заканчиваю работу!\n";
exit; # завершение выполнения программы
}
Выполнение примера сопровождается выводом сообщений, подтверждающих обработку поступившего сигнала:
Работаю в поте лица...
Получен сигнал INT по нажатию Ctrl+C
Заканчиваю работу!
Примером реальной программы, выполняющейся в бесконечном цикле, может служить любой сервер, ожидающий запросов от клиентских программ и перечитывающий свой конфигурационный файл после получения определенного сигнала (обычно HUP или USR1). Если необходимо временно игнорировать какой-то сигнал, то соответствующему элементу хэша %SIG присваивается строка 'IGNORE'. Восстановить стандартную обработку сигнала можно, присвоив соответствующему элементу %SIG строку 'DEFAULT'.
Процесс может посылать сигналы самому себе, например, для отслеживания окончания запланированного периода времени (для обработки тайм-аута). В приведенном примере длительная операция прерывается по истечении указанного промежутка времени:
# устанавливаем обработчик сигнала ALRM (будильник)
$SIG{ALRM} = sub { die "Timeout"; }; # анонимная подпрограмма
$timeout = 3600; # определяем величину тайм-аута (сек.)
eval { # блок обработки возможной ошибки
alarm($timeout); # устанавливаем время отправки сигнала
# некая длительная операция:
print "Работаю в поте лица...\n" while (1);
alarm(0); # нормальное завершение операции
};
# в специальной переменной $@ - сообщение об ошибке
if ($@ =~ /Timeout/) { # проверяем причину ошибки
print "Аварийный выход по истечении времени!";
}
Отправка сигнала одним процессом другому также используется в качестве средства взаимодействия процессов. Сигнал отправляется процессу с помощью функции kill(), которой передаются два аргумента: номер сигнала и PID процесса. Схему реагирования порожденного процесса на сигналы, получаемые от процесса-предка, можно увидеть на следующем учебном примере:
my $parent = $$; # PID родительского процесса
my $pid = fork(); # 'разветвить' текущий процесс
# fork вернет PID потомка в процессе-предке и 0 в потомке
die "fork не отработал: $!" unless defined $pid;
if ($pid) { # ---------- родительский процесс ----------
print "Начался предок PID $$\n";
for (1..3) {
print "Предок PID $$ работает $_\n";
print "Предок PID $$ отправил сигнал\n";
kill HUP, $pid;
sleep 2; # 'заснуть' на 2 секунды
}
print "Закончился предок (PID $$)\n";
}
unless ($pid) { # ---------- дочерний процесс ----------
my $counter = 0; # счетчик полученных сигналов
$SIG{HUP} = sub { ### обработчик сигнала ###
$counter++;
print "\tПотомок получил $counter-й сигнал!\n";
}; ### конец обработчика сигнала ###
print "\tНачался потомок PID $$ предка $parent\n";
for (1..7) {
print "\tПотомок PID $$ работает $_\n";
sleep 1; # 'заснуть' на 1 секунду
}
print "\tЗакончился потомок PID $$\n";
}
Поведение этих процессов во время выполнения программы можно проследить по выводимым ими сообщениям:
Начался потомок PID -800 предка 696
Потомок PID -800 работает 1
Начался предок PID 696
Предок PID 696 работает 1
Предок PID 696 отправил сигнал
Потомок получил 1-й сигнал!
Потомок PID -800 работает 2
Предок PID 696 работает 2
Предок PID 696 отправил сигнал
Потомок PID -800 работает 3
Потомок получил 2-й сигнал!
Потомок PID -800 работает 4
Предок PID 696 работает 3
Предок PID 696 отправил сигнал
Потомок PID -800 работает 5
Потомок получил 3-й сигнал!
Потомок PID -800 работает 6
Закончился предок (PID 696)
Потомок PID -800 работает 7
Закончился потомок PID -800
Сигналы нельзя считать слишком надежным и информативным средством обмена информацией: для передачи данных лучше использовать другие способы. Зато можно проверить состояние дочернего процесса, отправив ему особый нулевой сигнал функцией kill(0, $pid). Этот вызов не влияет на выполнение процесса-потомка, но возвращает истину (1), если процесс "жив", и ложь (0), если он завершился или ему нельзя посылать сигналы. Одинаковая реакция на нулевой сигнал гарантируется на различных платформах. Кроме того, можно прекратить выполнение дочернего процесса, отправив ему сигнал KILL вызовом kill(KILL, $pid).
Многопоточное выполнение - нити
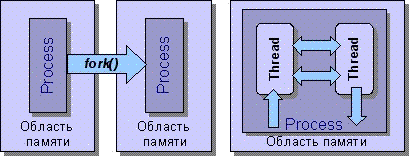
В последних версиях Perl появилась еще одна модель многозадачности - легковесные процессы (light-weight processes), называемые также потоками управления или нитями. (По-английски фраза "Perl threads" звучит как каламбур и может быть переведена как "нитки жемчуга" или "жемчужные ожерелья"). Нити отличаются от полновесных процессов с независимыми ресурсами тем, что выполняются в рамках одного процесса в единой области памяти. Поэтому создание нити происходит быстрее запуска отдельного процесса и требует меньше ресурсов операционной системы. Выполнение нитей в одной области памяти позволяет эффективно организовать совместный доступ к разделяемым данным. Кроме того, программист получает более полный контроль над параллельно выполняющимися потоками управления. Принципиальное различие между полновесными процессами, созданными операционной системой, и многопоточными нитями показано на рис. 16.1.
Рис. 16.1. Полновесные процессы и нити (потоки управления)
Существует несколько моделей многопоточной обработки, например DEC, Java, POSIX, Win32. Perl предлагает свою модель многопоточного программирования, отличающуюся от перечисленных и имеющую свои достоинства и недостатки. Появление в Perl кросс-платформенных средств работы с легковесными процессами стало несомненным достижением, которое заставило по-новому взглянуть на программирование параллельных процессов. Применение легковесных процессов позволяет разрабатывать эффективные приложения, одинаково выполняющиеся на разных платформах.
Работать с легковесными процессами просто. Подключив средства работы с нитями прагмой use threads, можно создать нить с помощью метода threads->new (синоним: threads->create). Этому методу передается ссылка на именованную или анонимную подпрограмму, которая запускается на выполнение в виде параллельного потока управления. Результатом создания нити станет ссылка на объект типа threads, который будет использоваться для управления потоком. Создание нити выглядит так:
use threads; # подключить многопоточные средства
my $thread = threads->new(\&pearl_thread); # запустить нить
sub pearl_thread { # эта подпрограмма
print "Это нить.\n"; # будет выполняться как нить
} #
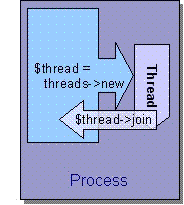
Итак, в определенной точке программы нить начала выполняться параллельно действиям в основной программе. Куда же должен произойти возврат, когда нить завершится? Это задается в основной программе с помощью метода join, который приостанавливает работу программы до завершения выполнения нити и возвращает результат, вычисленный нитью:
@result = $thread->join;
Действие, выполняемое методом join, называется "присоединение нити" или "объединение потоков". Как это происходит, показано на рис. 16.2.
Рис. 16.2. Присоединение нити с помощью join()
Каждой нити присваивается числовой идентификатор (Thread Identifier, TID), который можно получить с помощью метода tid. Создание нескольких нитей, объединение потоков и возврат значений из параллельно выполняющихся подпрограмм можно показать на таком примере:
use threads; # подключить многопоточные средства
my @thread = (); # массив объектов типа threads
for (my $i = 0; $i <= 2; $i++) { # создаем 3 нити
$thread[$i] = threads->new(\&pearl_thread, $i);
print "Создана $i-я нить. TID=", $thread[$i]->tid, "\n";
}
for (my $i = 2; $i >= 0; $i--) { # присоединяем нити
print "$i-я нить вернула ", $thread[$i]->join, "\n";
}
sub pearl_thread ($) { # нить получает
my $number = shift; # число, генерирует
my $random = int(rand(7)) + 1; # случайное значение,
print "\t$number-я нить ждет $random сек.\n";
sleep $random; # и, подождав немного,
return $random; # возвращает его
}
Сообщения, выводимые при выполнении этой программы, подтверждают независимое выполнение нитей и основной программы:
Создана 0-я нить. TID=1
Создана 1-я нить. TID=2
1-я нить ждет 7 сек.
0-я нить ждет 1 сек.
Создана 2-я нить. TID=3
2-я нить ждет 3 сек.
2-я нить вернула 3
1-я нить вернула 7
0-я нить вернула 1
Параллельно выполняющийся поток можно "отсоединить", игнорируя его значение: это делается методом $thread->detach, после выполнения которого присоединить нить будет невозможно.
Нити, выполняющиеся параллельно с основной программой, могут иметь доступ к общим переменным: скалярам, массивам и хэшам. Это делается с помощью явного указания для разделяемой переменной атрибута shared. Помеченная этим атрибутом переменная будет доступна для чтения и изменения в параллельном потоке. Для остальных переменных при отсоединении нити создаются локальные для каждого потока копии. Это демонстрируется таким примитивным примером:
use threads; # подключить многопоточные средства
use threads::shared; # и средства разделения данных
my $public : shared = 0; # разделяемая переменная
my $private = 0; # неразделяемая переменная
threads->new(sub { # нить из анонимной подпрограммы
$public++; $private++; # изменяем значения
print "$public $private\n"; # будет выведено: 1 1
})->join; # дожидаемся результатов выполнения:
print "$public ", # 1 ($public изменена в нити)
"$private\n"; # 0 (в нити изменена копия $private)
Чтобы предотвратить в одной нити изменение другими нитями значения разделяемой переменной, эту переменную нужно заблокировать при помощи функции lock(). Разблокирование переменной происходит не с помощью функции, а при выходе из блока, в котором она была заблокирована. Это делается таким образом:
{ # блок для работы с разделяемой переменной
lock $variable; # заблокировать переменную
$variable = $new_value; # и изменить ее значение
} # здесь $variable автоматически разблокируется
Нити могут обмениваться между собой данными. Например, с помощью стандартного модуля Thread::Queue организуется очередь для синхронизированной передачи данных из одной нити в другую. Пользоваться такой очередью гораздо проще, чем рассмотренными ранее программными каналами. Небольшой пример показывает, как помещать скалярные величины в очередь методом enqueue() и извлекать из нее методом dequeue(). Метод pending() возвращает число оставшихся в очереди элементов, поэтому может использоваться для окончания цикла чтения из очереди:
use threads; # подключить средства
use Thread::Queue; # и модуль работы с очередью
my $data_queue = Thread::Queue->new; # создаем очередь
my $thread = threads->new(\&reader); # и нить
# помещаем в очередь скалярные данные:
$data_queue->enqueue(1987); # число
$data_queue->enqueue('год'); # строку
$data_queue->enqueue('рождения', 'Perl'); # список
$thread->join; # ожидаем окончания нити
exit; # перед завершением программы
sub reader { # извлекаем данные из очереди,
while ($data_queue->pending) { # пока она не пуста
my $data_element = $data_queue->dequeue;
print "'$data_element' извлечен из очереди\n";
}
}
Автоматическая синхронизация доступа к очереди гарантирует очередность записи в очередь и чтение из нее, что видно из выполнения этого примера:
'1987' извлечен из очереди
'год' извлечен из очереди
'рождения' извлечен из очереди
'Perl' извлечен из очереди
Конечно, имеющиеся в Perl средства работы с легковесными процессами не ограничиваются перечисленными выше. Стандартные модули предоставляют и другие возможности эффективно организовать различные алгоритмы многопоточной обработки, не говоря уже о дополнительных модулях, имеющихся в архивах CPAN.
Существует много ситуаций, когда применение многозадачности не только оправданно, но и является единственно правильным решением задачи. Поэтому знание средств управления процессами дает вам новую точку зрения на решаемую проблему и расширяет ваш арсенал программных инструментов. В 6-й версии языка Perl средства распределенного программирования будут улучшены и дополнены, появятся сопрограммы (co-routines) и другие интересные возможности.
|

 Посмотреть
порно видео в онлайне »
Посмотреть
порно видео в онлайне »