| Основной критерий для
валидного документа
Каждый XML-документ должен
быть корректно сформированным, т.е. отвечать
минимальным требованиям по составлению XML-документа.
Если документ не является корректно
сформированным, он не может считаться XML-документом.
Корректно
сформированный XML-документ также может быть
валидным. Валидным (valid) называется корректно
сформированный (well-formed) документ,
отвечающий двум дополнительным требованиям:
- пролог документа
должен содержать специальное объявление типа
документа, которое содержит определение типа
документа (DTD), задающее структуру
документа;
- остальной документ
должен отвечать структуре, заданной в DTD.
В последующих
разделах этой лекции, а также в лекции 6, вы
узнаете, как создавать документы, отвечающие
этим двум общим требованиям.
Требования корректности
формирования и валидности
Требования
корректности формирования представляют собой
набор правил, определенных в спецификации XML,
которым вы должны следовать – в дополнение к
основным синтаксическим требованиям – чтобы
создать правильно составленный документ.
Поскольку XML-документ должен быть корректно
сформированным, любое отклонение от требований
корректности формирования считается фатальной
ошибкой (fatal error). Если XML-процессор
сталкивается с фатальной ошибкой, он должен
остановить нормальную обработку документа и не
пытаться ее возобновить.
Требования
валидности представляют собой дополнительный
набор правил в спецификации XML, которым вы
должны следовать, чтобы создать валидный
документ. Поскольку валидность является не
обязательной для XML-документа, отклонение от
требований валидности считается лишь ошибкой
(error), но не фатальным сбоем. Если XML-процессор
встречает ошибку, он может просто выдать
сообщение о ней и продолжить выполнение
обработки. Требования валидности состоят из
специальных правил по созданию соответствующего
объявления типа с его DTD, а также созданию
документа, отвечающего описанию внутри вашего
DTD.
Преимущества
использования валидных XML-документов
Может
показаться, что при создании валидного XML-документа
выполняется ряд лишних действий: вы должны
сначала полностью описать структуру документа в
DTD, а затем создать сам документ, отвечающий
всем спецификациям, содержащимся в DTD. Может
сложиться впечатление, что гораздо проще
непосредственно добавлять любые необходимые
элементы и атрибуты, как вы это делали в
примерах, работая с корректно сформированными
документами в предыдущих лекциях.
Однако, если
вы хотите быть уверенным, что ваш документ
отвечает определенной структуре или набору
стандартов, включение DTD, которое описывает эту
структуру, дает возможность XML-процессору (например,
Microsoft Internet Explorer 5) проверить,
соответствует ли документ структуре. Другими
словами, DTD обеспечивает стандартный шаблон для
процессора, чтобы при проверке валидности он мог
следовать требуемой структуре и гарантировать,
что ваш документ соответствует установленным
стандартам. Если какая-либо часть документа не
отвечает DTD-спецификации, процессор может
отобразить сообщение об ошибке, чтобы вы могли
отредактировать документ и исправить
несоответствия.
Использование валидных документов особенно
полезно для проверки однородности среди группы
схожих документов. Фактически, стандарт XML
определяет DTD как "грамматику для определенного
класса документов".
Предположим,
компании, занимающейся публикацией в Web,
требуется, чтобы все ее редакторы создавали XML-документы,
отвечающие единой структуре. Создание одного DTD
и включение его во все документы может
обеспечить условия соответствия документов
требуемой структуре, в то время как редакторы
будут избавлены от необходимости добавлять новые
элементы, помещать информацию в неправильном
порядке, присваивать неправильные типы данных и
т.д. Конечно, валидность документа должна быть
проверена при его обработке процессором.
Включение
DTD и проверка валидности имеют особое значение,
если документ будет обрабатываться программой
пользователя, ориентированной на определенную
структуру документа. Если все пользователи
программного обеспечения включат в свои XML-документы
соответствующие DTD, и все документы пройдут
проверку на валидность, то пользователи могут
быть уверены, что их документы будут распознаны
программой-обработчиком. Например, если группа
математиков создает математические документы,
которые будут отображаться специальной
программой, все они могут включить в свои
документы одинаковые DTD, которые содержат
определения требуемой структуры, элементов,
атрибутов и других компонентов.
На деле
большинство реальных XML-приложений, список
которых приведен в конце лекции 1, например,
MathML, состоят из стандартного DTD, которое все
пользователи приложения включают в свои XML-документы,
чтобы при проверке валидности обеспечивалось
соответствие структуре приложения, и документы
были распознаны любой программой, разработанной
для этого приложения.
Совет.
Если вы открываете XML-документ (самостоятельный
или с присоединенной таблицей стилей)
непосредственно в Internet Explorer 5, процессор
Internet Explorer 5 проверяет весь документ (в
том числе объявление типа документа, если оно
присутствует) на корректность формы составления,
и выводит сообщение о фатальной ошибке при любом
обнаруженном несоответствии. Однако процессор
Internet Explorer 5 не проверяет документ на
валидность.
Чтобы
проверить документ на валидность, вы можете
использовать сценарий проверки на валидность,
приведенный в лекции 9 в разделе "Проверка
валидности XML-документа". Вы можете прочесть
приведенные в этом разделе указания сейчас,
чтобы иметь возможность осуществлять проверку на
валидность создаваемых вами XML-документов.
Добавление DTD
Объявление
типа документа представляет собой блок XML-разметки,
который вы должны добавить в пролог валидного
XML-документа. Он может располагаться в любом
месте пролога – вне другой разметки – после XML-объявления,
как показано на рисунке 5.1. (Напомним, что если
вы включаете XML-объявление, оно должно
располагаться в начале документа.)
Рис. 5.1.
Объявление
типа документа определяет структуру документа.
Если вы открываете документ, не содержащий
объявления типа, в Internet Explorer 5,
процессор Internet Explorer 5 всего лишь
осуществляет проверку документа на корректность
формы составления. Если же вы открываете
документ, содержащий объявление типа документа,
процессор Internet Explorer 5 будет проверять
документ на валидность вместе с проверкой на
корректность формы составления, так что ваш
документ должен отвечать всем имеющимся
декларациям в объявлении типа документа. Так, вы
не сможете включить в документ какие-либо
элементы или атрибуты, если вы не объявили их в
объявлении типа документа. Каждый элемент и
атрибут, который вы включаете, должен
соответствовать спецификации (например,
допустимости применения данного содержимого
элемента или типа атрибута), выраженной в
соответствующем объявлении.
Примечание. Процессор
Internet Explorer 5 проверяет документ на
валидность только в том случае, если вы
открываете документ через HTML Web-страницу
(с использованием техники, с которой вы
познакомитесь в лекциях 8 и 9). Если вы
открываете XML-документ непосредственно в
Internet Explorer 5, процессор будет
проверять документ (включая любое объявление
типа документа, которое он содержит) на
корректность формы составления, но не будет
проверять документ на валидность, даже если
он содержит объявление типа документа.
Форма записи DTD
Объявление
типа документа имеет следующую обобщенную форму
записи:
<!DOCTYPE Имя DTD>
Здесь Имя
указывает на имя элемента Документ. Имя
действительного элемента Документ должно в
точности соответствовать имени, записанному в
объявлении. (Правила, в соответствии с которыми
следует выбирать имена элементов, приведены в
разделе "Анатомия элемента" в лекции 3.)
Например, если вы создаете объявление типа
документа для документа, рассмотренного в
предыдущем разделе, вам следует использовать имя
INVENTORY:
<!DOCTYPE INVENTORY
DTD>
(Это еще не
законченное объявление типа документа. DTD
следует заменить реальным содержимым.)
DTD
представляет собой определение типа документа,
которое содержит объявления, задающие элементы
документа, атрибуты и другие компоненты. В
следующем разделе вы познакомитесь с формой
записи их.
Примечание. Подобно
всем ключевым словам XML, DOCTYPE должно
быть набрано прописными буквами.
Создание DTD
DTD состоит
из символа левой квадратной скобки ([), после
которой следует ряд объявлений разметки,
заканчивающихся правой квадратной скобкой (]).
Объявления разметки описывают логическую
структуру документа; т.е. задают элементы
документа, атрибуты и другие компоненты. На
рисунке 5.2 приведен законченный валидный XML-документ,
содержащий DTD с единственным объявлением
разметки, которое определяет один тип элемента в
документе, SIMPLE.
Рис. 5.2.
DTD в этом
примере документа указывает, что документ может
содержать только элементы типа
SIMPLE (это
единственный заданный тип элемента), и что
элемент SIMPLE
может иметь любое допустимое для данного типа
содержимое (ключевое слово
ANY).
DTD может
содержать следующие типы объявлений разметки.
- Объявления
типов элементов. Они определяют типы
элементов, которые может содержать документ,
а также содержимое и порядок следования
элементов. Об объявлениях типов элементов
пойдет речь в следующем разделе.
- Объявления
списков атрибутов. Каждое объявление
списков атрибутов задает имена атрибутов,
которые могут быть использованы с
определенным типом элемента, а также типы
данных и устанавливаемые по умолчанию
значения этих атрибутов. Об этих объявлениях
будет рассказано далее в этой лекции.
- Объявления
примитивов. Вы можете использовать
примитивы для хранения часто используемых
фрагментов текста или для встраивания не
относящихся к XML данных в ваш документ. Об
объявлениях примитивов будет рассказано в
лекции 6.
- Объявления
нотаций. Нотация описывает формат данных
или идентифицирует программу, используемую
для обработки определенного формата. Об
объявлениях нотаций пойдет речь в лекции 6.
- Инструкции по
обработке. Эта тема затрагивалась в
разделе "Использование инструкций по
обработке" в лекции 4.
- Комментарии.
О них говорилось в разделе "Добавление
комментариев" в лекции 4.
- Ссылки на
параметрические примитивы. Любой из
приведенных выше компонентов может
содержаться внутри параметрического
примитива и добавляться путем ссылки на
параметрический примитив. Смысл этого
оператора станет вам понятен, когда вы
познакомитесь с материалом из лекции 6.
Данный пункт приведен здесь для полноты
картины.
Примечание. Типы DTD,
обсуждаемые в этом разделе (и используемые в
примерах в последующих разделах) относятся к
внутреннему подмножеству DTD, поскольку
полностью включаются в объявление типа
данного документа. В конце этой лекции вы
узнаете, как использовать DTD, размещенные в
отдельном файле, и относящиеся к внешнему
подмножеству DTD.
Объявление типов
элементов
В валидном
XML-документе вы должны полностью объявить тип
каждого элемента, который вы используете в
документе, в объявлении типа элемента внутри DTD.
Объявление типа элемента указывает на имя типа
элемента и допустимое содержимое элемента (часто
описывающее порядок размещения дочерних
элементов). Как единое целое, объявление типа
элемента в DTD – подобно построению базы данных
– задает полную логическую структуру документа.
Таким образом, объявление типа элемента
указывает на типы элементов, которые содержит
документ, порядок следования элементов, а также
описание содержимого элементов.
Форма записи объявления
типа элемента
Объявление
типа элемента имеет следующую обобщенную форму:
<!ELEMENT Имя
опись_содержимого>
Здесь Имя
есть имя объявляемого типа элемента. (Свод
правил по правильному заданию имен элементов
приведен в разделе "Анатомия элемента" в лекции
3.) Опись_содержимого – это описание содержимого,
которое определяет, что может содержать элемент.
В следующем разделе приведены различные типы
описаний содержимого, которые вы можете
использовать.
Ниже
приведено объявление типа элемента с именем
TITLE, для содержимого которого могут
использоваться только символьные данные (дочерние
элементы не допускаются):
<!ELEMENT TITLE (#PCDATA)>
А вот
объявление для типа элемента с именем
GENERAL,
содержимое которого может быть любым:
<!ELEMENT GENERAL ANY>
В качестве
последнего примера рассмотрим законченный XML-документ
с двумя типами элементов. Объявление типа
элемента COLLECTION указывает, что он может
содержать один или несколько элементов CD, а
объявление типа элемента CD указывает, что он
может содержать только символьные данные.
Заметим, что документ соответствует этим
объявлениям, и, следовательно, является валидным:
<?xml version="1.0"?>
<!DOCTYPE COLLECTION
[
<!ELEMENT COLLECTION (CD)+>
<!ELEMENT CD (#PCDATA)>
<!-- Вы также можете включать комментарии в DTD. -->
]
>
<COLLECTION>
<CD>Mozart Violin Concertos 1, 2, and 3</CD>
<CD>Telemann Trumpet Concertos</CD>
<CD>Handel Concerti Grossi Op. 3</CD>
</COLLECTION>
Примечание. Вы можете
объявить определенный тип элемента в данном
документе только один раз.
Описание содержимого
элемента
Вы можете
описать содержимое элемента – т.е. заполнить
часть опись_содержимого в объявлении типа
элемента – четырьмя различными способами.
- Пустое содержимое
(EMPTY).
Ключевое слово EMPTY
указывает, что элемент должен быть пустым –
т.е. не может иметь содержимого. Например:
<!ELEMENT IMAGE
EMPTY>
Ниже
приведены валидные элементы IMAGE, которые
вы можете поместить в документ:
<IMAGE></IMAGE>
<IMAGE />
- Любое содержимое
(ANY). Ключевое слово
ANY указывает, что элемент может
иметь любое допустимое для этого типа
содержимое. То есть элемент этого типа может
содержать или не содержать дочерние элементы
в любом порядке и с любым количеством
вхождений, иметь или не иметь чередующиеся
символьные данные. Это наиболее
неопределенный тип описания содержимого и
дает возможность создавать типы элементов
без ограничений на их содержимое. Вот пример
соответствующего объявления:
<!ELEMENT MISC
ANY>
- Содержимое
элемента (также называемое дочернее
содержимое). При таком описании типа
содержимого элемент может содержать дочерние
элементы, но не может непосредственно
содержать символьные данные. Об этой
возможности будет говориться в следующем
разделе.
- Смешанное
содержимое. При этом описании типа
содержимого элемент может содержать любое
количество смешанных данных, в том числе и
чередующихся с дочерними элементами
определенных типов. Эта возможность будет
описана далее в данной лекции.
Задание содержимого
элемента
Если элемент
имеет содержимое, он может непосредственно
содержать только определенные дочерние элементы,
но не символьные данные. В тексте документа вы
можете разделять дочерние элементы пробелами,
чтобы улучшить восприятие документа, но
процессор будет игнорировать символы пробела и
не передаст их приложению.
Рассмотрим
следующий пример XML-документа, описывающий одну
книгу:
<?xml version="1.0"?>
<!DOCTYPE BOOK
[
<!ELEMENT BOOK (TITLE, AUTHOR)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT AUTHOR (#PCDATA)>
]
>
<BOOK>
<TITLE>The Scarlet Letter</TITLE>
<AUTHOR>Nathaniel Hawthorne</AUTHOR>
</BOOK>
В этом
документе тип элемента
BOOK объявлен как имеющий содержимое
элемента. (TITLE,
AUTHOR), следующие
за именем элемента в объявлении, составляют
модель содержимого. Модель содержимого указывает
на разрешенные типы дочерних элементов и их
порядок. В этом примере модель содержимого
указывает на то, что элемент
BOOK должен иметь
ровно один дочерний элемент
TITLE, за которым
следует ровно один дочерний элемент
AUTHOR. При
обработке документа процессор игнорирует три
пустых строки, используемые для разделения
дочерних элементов внутри элемента
BOOK.
Модель
содержимого может иметь одну из следующих
основных форм.
- Последовательная.
Последовательная форма модели содержимого
указывает, что элемент должен иметь заданную
последовательность дочерних элементов. Вы
отделяете имена типов дочерних элементов
запятыми. Например, следующее DTD указывает,
что элемент MOUNTAIN
должен иметь один дочерний элемент
NAME, после
которого идет один дочерний элемент
HEIGHT, за
которым следует один дочерний элемент
STATE:
<!DOCTYPE MOUNTAIN
[
<!ELEMENT MOUNTAIN (NAME, HEIGHT, STATE)>
<!ELEMENT NAME (#PCDATA)>
<!ELEMENT HEIGHT (#PCDATA)>
<!ELEMENT STATE (#PCDATA)>
]
>
Следовательно, следующий элемент Документ
будет валидным:
<MOUNTAIN>
<NAME>Wheeler</NAME>
<HEIGHT>13161</HEIGHT>
<STATE>New Mexico</STATE>
</MOUNTAIN>
Следующий элемент Документ, однако, не будет
валидным, поскольку порядок дочерних
элементов не соответствует объявленному:
<MOUNTAIN>
<!-- Неправильный элемент! -->
<STATE>New Mexico</STATE>
<NAME>Wheeler</NAME>
<HEIGHT>13161</HEIGHT>
</MOUNTAIN>
Пропуск
дочернего элемента или использование одного
и того же типа дочернего элемента более
одного раза также недопустимо. Как вы видите,
это достаточно строгий вид объявления.
- Выборочная.
Выборочная форма модели содержимого
указывает, что элемент может иметь любой из
серии допустимых дочерних элементов,
разделяемых символом |. Например, следующее
DTD указывает, что элемент
FILM может
состоять из одного дочернего элемента
STAR, или
одного дочернего элемента
NARRATOR, или
одного дочернего элемента
INSTRUCTOR:
<!DOCTYPE FILM
[
<!ELEMENT FILM (STAR | NARRATOR |
INSTRUCTOR)>
<!ELEMENT STAR (#PCDATA)>
<!ELEMENT NARRATOR (#PCDATA)>
<!ELEMENT INSTRUCTOR (#PCDATA)>
]
>
Следовательно, следующий элемент Документ
будет валидным:
<FILM>
<STAR>Robert Redford</STAR>
</FILM>
как и
элемент:
<FILM>
<NARRATOR>Sir Gregory Parsloe</NARRATOR>
</FILM>
а также
элемент:
<FILM>
<INSTRUCTOR>Galahad Threepwood</INSTRUCTOR>
</FILM>
Следующий элемент Документ не будет валидным,
поскольку вы можете включить только один из
дочерних элементов:
<FILM> <!--
Неправильный элемент! -->
<NARRATOR>Sir Gregory Parsloe</NARRATOR>
<INSTRUCTOR>Galahad Threepwood</INSTRUCTOR>
</FILM>
Вы
можете изменить любую из этих форм модели
содержимого, используя символы: знак вопроса
(?), знак плюс (+) и звездочка (*), значения
которых описаны в следующей таблице:
| Символ |
Значение |
|
? |
Ни одного или один из
предшествующих элементов |
|
+ |
Один или более из предшествующих
элементов |
|
* |
Ни одного или более из
предшествующих элементов |
Например, следующее объявление означает, что
вы можете включить один или более дочерних
элементов NAME,
и что дочерний элемент HEIGHT является не
обязательным:
<!ELEMENT MOUNTAIN
(NAME+, HEIGHT?, STATE)>
Таким
образом, следующий элемент будет правильным:
<MOUNTAIN>
<NAME>Pueblo Peak</NAME>
<NAME>Taos Mountain</NAME>
<STATE>New Mexico</STATE>
</MOUNTAIN>
Другой
пример: следующее объявление означает, что
вы можете включить несколько или ни одного
дочернего элемента
STAR, либо один дочерний элемент
NARRATOR, либо
один дочерний элемент
INSTRUCTOR:
<!ELEMENT FILM
(STAR* | NARRATOR |
INSTRUCTOR)>
Соответственно, каждый из следующих трех
элементов будет корректным:
<FILM>
<STAR>Tom Hanks</STAR>
<STAR>Meg Ryan</STAR>
</FILM>
<FILM>
<NARRATOR>Sir Gregory Parsloe</NARRATOR>
</FILM>
<FILM/>
Вы
также можете воспользоваться символами ?, +
или * для модификации всей модели
содержимого, помещая символы непосредственно
после закрывающих скобок. Например,
следующее объявление дает вам возможность
включить один или несколько дочерних
элементов любого из этих трех типов в любом
порядке:
<!ELEMENT FILM
(STAR | NARRATOR |
INSTRUCTOR)+>
Такое
объявление делает корректными следующие
элементы:
<FILM>
<NARRATOR>Bertram Wooster</NARRATOR>
<STAR>Sean Connery</STAR>
<NARRATOR>Plug Basham</NARRATOR>
</FILM>
<FILM>
<STAR>Sean Connery</STAR>
<STAR>Meg Ryan</STAR>
</FILM>
<FILM>
<INSTRUCTOR>Stinker Pike</INSTRUCTOR>
</FILM>
Наконец, вы можете формировать более сложные
модели содержимого путем вложения выборочной
модели содержимого внутрь последовательной
модели, либо последовательной модели в
выборочную модель. Например, следующее DTD
задает, что каждый элемент
FILM должен
иметь один дочерний элемент
TITLE; за ним
должен следовать один дочерний элемент
CLASS; после
него должен идти один дочерний элемент
STAR,
NARRATOR или
INSTRUCTOR:
<!DOCTYPE FILM
[
<!ELEMENT FILM (TITLE, CLASS, (STAR | NARRATOR |
INSTRUCTOR) )>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT CLASS (#PCDATA)>
<!ELEMENT STAR (#PCDATA)>
<!ELEMENT NARRATOR (#PCDATA)>
<!ELEMENT INSTRUCTOR (#PCDATA)>
]
>
В
соответствии с этим DTD, следующий элемент
Документ будет корректным:
<FILM>
<TITLE>The Net</TITLE>
<CLASS>fictional</CLASS>
<STAR>Sandra Bullok</STAR>
</FILM>
так же,
как такой:
<FILM>
<TITLE>How to Use XML</TITLE>
<CLASS>instructional</CLASS>
<INSTRUCTOR>Penny Donaldson</INSTRUCTOR>
</FILM>
Задание смешанного
содержимого
Если
элемент имеет смешанное содержимое, он может
включать символьные данные. Если же вы зададите
в объявлении один или несколько типов дочерних
элементов, он может содержать любые из этих
дочерних элементов в любом порядке и с любым
количеством вхождений (нуль и более). Другими
словами, при смешанном содержимом вы можете
задавать типы дочерних элементов, но не можете
задавать порядок или количество вхождений
дочерних элементов, а также задавать
обязательность включения для определенных типов
дочерних элементов.
Чтобы
объявить тип элемента смешанного содержимого, вы
можете воспользоваться одной из следующих форм
модели содержимого.
- Только символьные
данные. Чтобы объявить тип элемента, который
может содержать только символьные данные,
используйте модель содержимого (#PCDATA).
Так, следующее объявление указывает, что для
элемента SUBTITLE
допускаются только символьные данные:
<!ELEMENT SUBTITLE
(#PCDATA)>
Следующие два элемента в соответствии с
данной декларацией являются корректными:
<SUBTITLE>A New
Approach</SUBTITLE>
<SUBTITLE></SUBTITLE>
Заметим,
что элемент, который в соответствии с
объявлением должен содержать символьные
данные, может и не иметь никаких символов –
т.е. быть пустым.
Примечание.
Ключевое слово
PCDATA относится к синтаксически
анализируемым (разбираемым) символьным
данным. Из лекции 3 вам известно, что
XML-процессор синтаксически разбирает
символьные данные внутри элемента – т.е.
сканирует элемент в поиске XML-разметки.
В связи с этим вы не можете использовать
левую угловую скобку (<) или знак
амперсанда (&) или символы ]]> как часть
символьных данных, поскольку
синтаксический анализатор будет
интерпретировать каждый из этих символов
или группы символов как разметку. Однако
вы можете использовать любые символы с
помощью ссылки на символ или на
предопределенный примитив (см. лекцию
6), либо с помощью раздела
CDATA (см.
лекцию 4).
- Символьные данные
с необязательными дочерними элементами.
Чтобы объявить тип элемента, который может
содержать символьные данные плюс ни одного
или несколько дочерних элементов,
перечислите каждый тип дочернего элемента
после ключевого слова
PCDATA в модели содержимого, разделяя
их символами ( и помещая звездочку (*) в
конце всей модели содержимого. Каждое имя
элемента может появляться в модели
содержимого только один раз. Например,
следующее объявление указывает, что элемент
TITLE может
содержать символьные данные плюс ни одного
или несколько дочерних элементов
SUBTITLE:
<!ELEMENT TITLE
(#PCDATA | SUBTITLE)*>
В
соответствии с этим объявлением следующие
элементы TITLE
являются допустимыми:
<TITLE>
Moby-Dick
<SUBTITLE>Or, the Whale</SUBTITLE>
</TITLE>
<TITLE>
<SUBTITLE>Or, the Whale</SUBTITLE>
Moby-Dick
</TITLE>
<TITLE>
Moby-Dick
</TITLE>
<TITLE>
<SUBTITLE>Or, the
Whale</SUBTITLE>
<SUBTITLE>Another
Subtitle</SUBTITLE>
</TITLE>
<TITLE></TITLE>
Объявление атрибутов
В валидном
XML-документе вы также должны исчерпывающе
объявить все атрибуты, которые вы предполагаете
использовать для элементов документа. Вы
определяете все атрибуты, ассоциированные с
определенным элементом, с помощью специального
типа DTD-разметки, называемого объявлением
списка атрибутов. Это объявление:
- определяет имена
атрибутов, ассоциированных с элементом. В
валидном документе вы можете включить в
начальный тег элемента только те атрибуты,
которые определены для элемента;
- устанавливает тип
данных каждого атрибута;
- задает
востребованность для каждого атрибута. Если
атрибут не востребован, в объявлении списка
атрибутов указывается, что должен делать
процессор, если атрибут опущен. (В
объявлении должно, например, содержаться
значение атрибута по умолчанию, которое
будет использовать процессор.)
Форма записи объявления
списка атрибутов
Объявление
списка атрибутов имеет следующую общую форму:
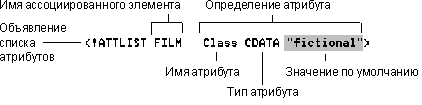
<!ATTLIST Имя ОпрАтр>
Здесь Имя
представляет собой имя элемента,
ассоциированного с атрибутом или атрибутами.
ОпрАтр – это одно или несколько определений
атрибутов, каждое из которых определяет один
атрибут.
Определение
атрибута имеет следующую форму записи:
Имя ОпрАтр ОбъявУмолч
Здесь Имя
представляет собой имя атрибута. (Правила выбора
имен атрибутов приведены в разделе "Правила
создания атрибутов" в лекции 3.)
ОпрАтр
представляет собой тип атрибута, т.е. виды
значений, которые могут быть присвоены атрибуту.
(О типах атрибутов пойдет речь в следующем
разделе.) ОбъявУмолч – это объявление по
умолчанию, которое указывает на востребованность
атрибута и содержит другую информацию. (Об этом
будет рассказано далее в этой лекции.)
Допустим,
вы объявили тип элемента с именем
FILM следующим
образом:
<!ELEMENT FILM (TITLE,
(STAR | NARRATOR |
INSTRUCTOR) )>
Вот пример
объявления списка атрибутов, которое описывает
два атрибута – Class
и Year – для
элемента FILM:
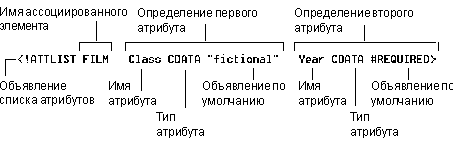
<!ATTLIST FILM
Class CDATA "fictional" Year CDATA
#REQUIRED>
На рисунке
5.3 представлены составные части этого
объявления.
Рис. 5.3.
Вы можете
присвоить атрибуту Class
любую строку в кавычках (ключевое слово
CDATA); если вы
опускаете атрибут для определенного элемента,
ему будет автоматически присвоено значение по
умолчанию "fictional". Вы можете присвоить
атрибуту Year
любую строку в кавычках; этот атрибут, однако,
должен быть обязательно присвоен для каждого
элемента FILM (ключевое
слово #REQUIRED),
поэтому он не имеет значения по умолчанию.
Следующий
полный XML-документ включает это объявление
списка атрибутов, а также элемент
FILM:
<?xml version="1.0"?>
<!DOCTYPE FILM
[
<!ELEMENT FILM (TITLE, (STAR | NARRATOR |
INSTRUCTOR) )>
<!ATTLIST FILM Class CDATA "fictional" Year
CDATA
#REQUIRED>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT STAR (#PCDATA)>
<!ELEMENT NARRATOR (#PCDATA)>
<!ELEMENT INSTRUCTOR (#PCDATA)>
]
>
<FILM Year="1948">
<TITLE>The Morning After</TITLE>
<STAR>Morgan Attenbury</STAR>
</FILM>
Для
элемента FILM
атрибуту Year
присвоено значение "1948". Атрибут
Class опущен;
однако, поскольку этот атрибут имеет значение по
умолчанию ("fictional"), оно присваивается
атрибуту, как если бы вы записали его в качестве
значения атрибута.
Примечание. Если вы
использовали для данного типа элемента более
одного объявления списка атрибутов,
содержания двух объявлений объединяются.
Если атрибут с заданным именем объявлен для
одного и того же элемента несколько раз,
первое объявление используется, а
последующие – игнорируются. (Множественные
объявления списков атрибутов могут иметь
место, если документ имеет как внутренние,
так и внешние DTD, о чем пойдет речь далее в
этой лекции.)
Тип атрибута
Тип
атрибута является вторым необходимым компонентом
в определении атрибута. Он задает вид значений,
которые вы можете присваивать атрибуту внутри
документа, как показано на рисунке 5.4.
Рис. 5.4.
Вы можете
задавать тип атрибута тремя различными способами.
Задание маркерного типа
Как и любое
значение атрибута, значение, которое вы
присваиваете маркерному типу атрибута, должно
представлять собой строку в кавычках, отвечающую
общим правилам, описанным в разделе "Правила для
корректного задания значений атрибутов" в лекции
3.
Кроме того,
значение должно отвечать определенному
ограничению, которое вы задаете в описании
атрибута с помощью соответствующего ключевого
слова. Например, в приведенном ниже XML-документе
для атрибута StockCode определен маркерный тип с
использованием ключевого слова ID. (ID – это
только одно из ключевых слов, которые вы можете
использовать для объявления маркерного типа.)
Это ключевое слово означает, что для каждого
элемента атрибуту должно быть присвоено
уникальное значение. (Например, присвоение
товарного кода "S021" двум элементам
ITEM не
допускается.)
<?xml version="1.0"?>
<!DOCTYPE INVENTORY
[
<!ELEMENT INVENTORY (ITEM*)>
<!ELEMENT ITEM (#PCDATA)>
<!ATTLIST ITEM StockCode ID #REQUIRED>
]
>
<INVENTORY>
<!-- Каждый элемент ITEM должен иметь свое значение кода StockCode
-->
<ITEM StockCode="S021">Peach Tea Pot</ITEM>
<ITEM StockCode="S034">Electric Cofee Grinder</ITEM>
<ITEM StockCode="S086">Candy Thermometer</ITEM>
</INVENTORY>
Ниже
приведен полный список ключевых слов, которые вы
можете использовать в определении маркерных
типов атрибутов, и ограничения, которые они
накладывают на значения атрибутов.
- ID. Для каждого
элемента атрибут должен иметь уникальное
значение. Значение должно начинаться с буквы
или символа подчеркивания (_), за которыми
могут идти или не идти другие буквы, цифры,
символы точки (.), тире (–) или символы
подчеркивания. Данный тип элемента может
иметь только один атрибут типа ID, а в
объявлении значения атрибута по умолчанию
должно фигурировать
#REQUIRED или
#IMPLIED (см. в разделе "Объявление
значения по умолчанию" далее в этой лекции).
Пример этого типа атрибута содержится в
приведенном выше документе
INVENTORY.
-
IDREF.
Значение атрибута должно совпадать со
значением атрибута элемента типа ID внутри
документа. Другими словами, этот тип
атрибута является ссылкой на уникальный
идентификатор другого атрибута. Например, вы
можете добавить атрибут
IDREF с именем
GoesWith к
элементу ITEM:
<!ELEMENT ITEM (#PCDATA)>
<!ATTLIST ITEM
StockCode ID #REQUIRED GoesWith IDREF #IMPLIED>
Далее
вы можете использовать этот атрибут для
ссылки на другой элемент
ITEM:
<ITEM
StockCode="S034">Electric Cofee
Grinder</ITEM>
<ITEM StockCode="S047" GoesWith="S034">
Cofee Grinder Brush
</ITEM>
- IDREFS. Этот тип
атрибута похож на тип
IDREF, но при этом значение может
включать ссылки на несколько идентификаторов
– разделенных пробелами – внутри строки в
кавычках. Например, если вы назначите
атрибуту GoesWith
тип IDREFS
таким образом:
<!ATTLIST ITEM
StockCode ID #REQUIRED GoesWith
IDREFS #IMPLIED>
то
можете использовать его на ссылки на
несколько других элементов:
<ITEM
StockCode="S034">Electric Cofee
Grinder</ITEM>
<ITEM StockCode="S039">
1 pound Breakfast Blend Cofee Beans
</ITEM>
<ITEM StockCode="S047" GoesWith="S034
S039">
Cofee Grinder Brush
</ITEM>
- ENTITY. Значение
атрибута должно совпадать с именем примитива,
объявленного в DTD. Этот примитив не
обрабатывается синтаксическим анализатором и
ссылается на внешний файл, обычно содержащий
не XML-данные. О таких примитивах будет
рассказано в лекции 6.
Например, в DTD вы объявляете элемент с
именем IMAGE,
представляющий графическое изображение, и
атрибут типа ENTITY
с именем Source,
указывающий на источник графических данных:
<!ELEMENT IMAGE
EMPTY>
<!ATTLIST IMAGE Source ENTITY
#REQUIRED>
Если вы
объявили не анализируемый примитив с именем
Logo (используя
технику, с которой вы познакомитесь в лекции
6), который содержит графические данные для
изображения, вы можете присвоить этот
примитив атрибуту
Source элемента
IMAGE в
документе следующим образом:
<IMAGE
Source="Logo" />
-
ENTITIES. Этот
тип атрибута похож на тип
ENTITY, за
исключением того, что значение может
содержать имена нескольких не анализируемых
примитивов – разделенных пробелами – внутри
строки в кавычках. Например, если вы
назначили атрибуту
Source тип
ENTITIES следующим образом:
<!ELEMENT IMAGE
EMPTY>
<!ATTLIST IMAGE Source ENTITIES
#REQUIRED>
то
сможете использовать его для ссылки на
несколько не анализируемых примитивов (допустим,
примитивов, содержащих графические данные в
альтернативных форматах), например, так:
<IMAGE Source="LogoGif
LogoBmp" />
(Здесь
подразумевается, что LogoGif и LogoBmp –
имена не анализируемых примитивов, которые
были объявлены в DTD с помощью приемов, с
которыми вы познакомитесь в лекции 6.)
-
NMTOKEN. Это
значение есть элементарное имя (name token),
представляющее собой имя, состоящее из одной
или более букв, цифр, точек (.), тире (–)
или символов подчеркивания (_). Элементарное
имя может также содержать двоеточие (:), но
не на первом месте. Например, если вы
назначите атрибуту
ISBN тип
NMTOKEN следующим образом:
<!ELEMENT BOOK (#PCDATA)>
<!ATTLIST BOOK ISBN NMTOKEN
#REQUIRED>
то
можете присвоить ему значение, начинающееся
с цифры (цифры в качестве первых символов
допустимы для типов
NMTOKEN и
NMTOKENS, но не для любых других
маркерных типов):
<BOOK
ISBN="9-99999-999-9">The Portrait of a
Lady</BOOK>
-
NMTOKENS. Этот
тип атрибута похож на тип
NMTOKEN, но
значение может содержать несколько
элементарных имен – разделенных пробелами –
внутри строки в кавычках. Например, если вы
назначите атрибуту Codes тип NMTOKENS
следующим образом:
<!ELEMENT SHIRT (#PCDATA)>
<!ATTLIST SHIRT Codes NMTOKENS
#REQUIRED>
вы
можете присвоить ему несколько значений в
виде элементарных имен:
<SHIRT Codes="38
21 97">long sleeve Henley</SHIRT>
Задание нумерованных
типов
Как любое
значение атрибута, значение, которое вы
присваиваете нумерованному типу, должно
представлять собой строку в кавычках, отвечающую
правилам, описанным в разделе "Правила для
корректного задания значений атрибутов" в лекции
3. Помимо этого, значение должно совпадать с
одним из имен, приведенных в списке типов
атрибутов. Эти имена могут иметь одну из
следующих двух форм записи.
- Открывающая скобка,
вслед за которой идет список элементарных
имен, разделенных символами | , после чего
следует закрывающая скобка. Напомним, что
элементарное имя – это имя, состоящее из
одной или нескольких букв, цифр, точек (.),
тире (–) или символов подчеркивания (_), а
также может включать одно двоеточие (:), но
не на первом месте. Например, если вы хотите
ограничить значения атрибута Class словами
"fictional", "instructional" или
"documentary", то можете определить это
атрибут как нумерованный тип следующим
образом:
<!ATTLIST FILM
Class (fictional | instructional |
documentary)
"fictional"
Вот
законченный XML-документ, демонстрирующий
использование атрибута Class:
<?xml
version="1.0"?>
<!DOCTYPE FILM
[
<!ELEMENT FILM (TITLE, (STAR | NARRATOR |
INSTRUCTOR) )>
<!ATTLIST FILM
Class (fictional | instructional
| documentary) "fictional">
<!ELEMENT TITLE (#PCDATA)
<!ELEMENT STAR (#PCDATA)
<!ELEMENT NARRATOR (#PCDATA)
<!ELEMENT INSTRUCTOR (#PCDATA)
]
>
<FILM Class="instructional">
<TITLE>The Use and Care of XML</TITLE>
<NARRATOR>Michael Young</NARRATOR>
</FILM>
Если вы
опустили атрибут
Class, ему будет по умолчанию
присвоено значение "fictional". Присвоение
атрибуту Class
значения, отличного от "fictional",
"instructional" или "documentary" приведет к
ошибке.
- Ключевое слово
NOTATION, за
которым идет пробел, затем открывающая
скобка, затем список имен нотаций,
разделяемых символами | , после чего следует
закрывающая скобка. Каждое из этих имен
должно точно соответствовать имени нотации,
объявленному в DTD. Нотация описывает формат
данных или идентифицирует программу,
применяемую для обработки определенного
формата (подробнее о нотациях будет
рассказано в лекции 6).
Например, в вашем DTD объявлены нотации
HTML, SGML и RTF. Тогда вы можете ограничить
значения атрибута Format одним из этих имен
нотаций с помощью следующего объявления:
<!ELEMENT
EXAMPLE_DOCUMENT (#PCDATA)>
<!ATTLIST EXAMPLE_DOCUMENT
Format NOTATION (HTML | SGML | RTF) #REQUIRED>
В
дальнейшем вы можете использовать элемент
Format для
указания формата определенного элемента
EXAMPLE_DOCUMENT,
как в следующем примере:
<EXAMPLE_DOCUMENT
Format="HTML">
<![CDATA[
<HTML>
<HEAD>
<TITLE>Mike’s Home Page</TITLE>
</HEAD>
<BODY>
<P>Welcome!</P>
</BODY>
</HTML>
]]>
</EXAMPLE_DOCUMENT>
Присвоение атрибуту
Format значения, отличного от "HTML",
"SGML" или "RTF", приведет к ошибке. (Обратите
внимание на использование здесь раздела
CDATA – при
этом вы можете свободно использовать символ
левой угловой скобки (<) внутри символьных
данных элемента.)
Объявление значения по
умолчанию
Объявление
значения по умолчанию – это третий и последний
обязательный компонент в определении атрибута.
Оно задает, является ли атрибут обязательным, и
если нет, указывает, что должен предпринимать
процессор в случае, когда атрибут опущен (см.
рис. 5.5). Так, объявление должно обеспечить
значение атрибута по умолчанию, которое будет
использовать процессор в том случае, если
атрибут отсутствует.
Рис. 5.5.
Объявление
значения по умолчанию может иметь следующие
четыре формы:
-
#REQUIRED. При
этой форме вы должны задать значение
атрибута для каждого элемента
ассоциированного типа. Например, следующее
объявление указывает, что вы должны
присвоить значение атрибуту
Class внутри
начального тега каждого элемента
FILM в
документе:
<!ATTLIST FILM
Class CDATA #REQUIRED>
-
#IMPLIED. Эта
форма указывает, что вы можете либо
включить, либо опустить атрибут для элемента
ассоциированного типа, а также, что если вы
опускаете атрибут, то никакое значение по
умолчанию процессору не передается. (Эта
форма "подразумевает", а не "устанавливает"
значение, позволяя приложению использовать
свое собственное значение по умолчанию –
т.е. имя.) Например, следующее объявление
указывает, что присвоение значения атрибуту
Class внутри элемента FILM является не
обязательным, и что в документе не
представлено значение Class по умолчанию:
<!ATTLIST FILM
Class CDATA #IMPLIED>
-
AttValue, где
AttValue – значение атрибута по
умолчанию. При такой форме вы можете либо
включить, либо опустить атрибут для элемента
ассоциированного типа. Если вы опускаете
атрибут, процессор использует значение по
умолчанию, как если бы вы включили атрибут и
задали это значение.
Задаваемое значение по умолчанию, конечно,
должно соответствовать заданному типу
атрибута. Например, следующее объявление
присваивает значение по умолчанию
"fictional" атрибуту Class:
<!ATTLIST FILM
Class CDATA "fictional">
Согласно этому объявлению следующие два
элемента эквивалентны:
<FILM>The
Graduate</FILM>
<FILM Class="fictional">The
Graduate</FILM>
-
#FIXED AttValue,
где AttValue –
значение атрибута по умолчанию. При такой
форме вы можете либо включать, либо опускать
атрибут для элемента ассоциированного типа.
Если вы опускаете атрибут, процессор будет
использовать значение, заданное по
умолчанию; если вы включаете атрибут, вы
должны задать значение по умолчанию.
(Поскольку вы можете задать только значение
по умолчанию, нет смысла включать в элемент
описание атрибута, за исключением желания
сделать документ более понятным для
восприятия.) Например, следующее объявление
присваивает фиксированное значение по
умолчанию атрибуту
Class:
<!ATTLIST FILM
Class CDATA #FIXED "documentary">
В
соответствии с этим объявлением следующие
два эквивалентных элемента будут
корректными:
<FILM>The Making
of XML</FILM>
<FILM Class="documentary">The Making of
XML</FILM>
в то
время как следующий элемент будет
некорректным:
<!-- Некорректный
элемент! -->
<FILM Class="instructional">The Making
of XML</FILM>
Использование внешних
подмножеств DTD
Описания
типа документа, рассмотренные нами в этой лекции,
полностью содержатся внутри объявления типа
документа в составе документа. Такой тип DTD
называется внутренним подмножеством DTD.
Вы также
можете поместить все или часть DTD документа в
отдельный файл, а затем ссылаться на этот файл
из объявления типа документа. DTD – или часть
DTD – содержащаяся в отдельном файле, называется
внешним подмножеством DTD.
Примечание. Применение
внешнего подмножества DTD имеет смысл
главным образом для DTD, которые являются
общими для целой группы документов. Каждый
документ может ссылаться на один файл DTD (или
копию этого файла) как на внешнее
подмножество DTD. При этом вам не надо
копировать содержимое DTD в каждый
использующий его документ, а также
облегчается внесение изменений в DTD. (Вам
требуется модифицировать только файл DTD – и
все копии этого файла – вместо того, чтобы
редактировать все документы, которые его
используют.) Как вам известно из лекции 1,
многие стандартные XML-приложения основаны
на общем DTD, включаемом во все XML-документы,
отвечающие этому приложению. (См. разделы "Стандартные
XML-приложения" и "Реальное использование
XML" в лекции 1.)
Использование только
внешнего подмножества DTD
Чтобы
использовать только внешнее подмножество DTD,
опустите блок объявлений разметки, ограниченных
квадратными скобками ([]), и вместо этого
включите ключевое слово
SYSTEM, после которого в кавычках должно
следовать описание местонахождения отдельного
файла, содержащего DTD. Рассмотрим, например,
документ SIMPLE,
используемый ранее в этой лекции и имеющий
внутреннее подмножество DTD:
<?xml version="1.0"?>
<!DOCTYPE SIMPLE
[
<!ELEMENT SIMPLE ANY>
]
>
<SIMPLE> This is an extremely simplistic XML
document. </SIMPLE>
Если в этом
документе используется внешнее подмножество DTD,
он будет иметь следующий вид:
<?xml version="1.0"?>
<!DOCTYPE SIMPLE SYSTEM "Simple.dtd">
<SIMPLE> This is an extremely simplistic XML
document. </SIMPLE>
Файл
Simple.dtd должен иметь следующее содержимое:
<!ELEMENT SIMPLE ANY>
Файл,
содержащий внешнее подмножество DTD, может
включать любые объявления разметки, которые
могут быть включены во внутреннее подмножество
DTD (см. раздел "Создание DTD" ранее в этой
лекции).
Описание
местонахождения файла (в данном примере
Simple.dtd) называется системным литералом. Он
может быть заключен в одинарные (') или двойные
(") кавычки и содержать любые символы, за
исключением символов кавычек, используемых как
ограничители.
Системный
литерал задает унифицированный идентификатор
ресурса (URI – uniform resource identifier)
файла, содержащего внешнее подмножество DTD. В
настоящее время URI практически аналогичен
стандартному Internet-адресу, известному как
унифицированный указатель ресурса (URL – Uniform
Resource Locator). Вы можете использовать
полностью прописанный URI, подобно следующему:
<!DOCTYPE SIMPLE
SYSTEM " HYPERLINK
"http://bogus.com/dtds/Simple.dtd"
http://bogus.com/dtds/Simple.dtd">
Или, вы
можете использовать частичный URI, который
задает местонахождение относительно
местонахождения XML-документа, содержащего URI,
например:
<!DOCTYPE SIMPLE
SYSTEM "Simple.dtd">
Примечание. URI
представляет собой чрезвычайно гибкую
систему нотации для адресации ресурсов.
Одним из типов URI является URL (Uniform
Resource Locator), обычно используемый в
Internet (например, http://bogus.com/documents/Simple.dtd.
Аналогично, если бы XML-документ был
расположен в HYPERLINK file:///C:\\XML ile:///C:\XML
Step by Step\Example Code\Simple.xml, "Simple.dtd"
ссылался бы на HYPERLINK file:///C:\\XML ile:///C:\XML
Step by Step\Example Code\Simple.dtd.
Использование и
внешних, и внутренних подмножеств DTD
Чтобы
использовать и внешнее и внутреннее подмножество
DTD, следует использовать ключевое слово
SYSTEM вместе с
системным литералом, задающим местонахождение
файла с внешним подмножеством DTD, после чего
внутри квадратных скобок ([]) следует объявление
разметки внутреннего подмножества DTD.
Вот пример
простого XML-документа, имеющего как внутреннее,
так и внешнее подмножество DTD:
<?xml version="1.0"?>
<!DOCTYPE BOOK SYSTEM "Book.dtd"
[
<!ATTLIST BOOK ISBN CDATA #IMPLIED Year CDATA "2000">
<!ELEMENT TITLE (#PCDATA)>
]
>
<BOOK Year="1998">
<TITLE>The Scarlet Letter</TITLE>
</BOOK>
Вот
содержимое файла Book.dtd, в котором хранится
внешнее подмножество DTD:
<!ELEMENT BOOK ANY>
<!ATTLIST BOOK ISBN NMTOKEN #REQUIRED>
Если вы
используете внешнее и внутреннее подмножество
DTD, XML-процессор объединяет их содержимое
следующим образом:
Примечание. Хотя XML-процессор
просто игнорирует повторные объявления
атрибутов и примитивов, повторное объявление
элемента (даже если он объявлен тем же самым
образом) является допустимым.
Способ
объединения внутреннего и внешнего подмножеств
DTD XML-процессором дает вам возможность
использовать общий DTD (например такой, который
используется для XML-приложений) в качестве
внешнего подмножества DTD, а затем адаптировать
(или субклассировать, как говорят программисты)
DTD для конкретного документа путем включения
внутреннего подмножества. Ваше внутреннее
подмножество может добавлять элементы, атрибуты
или примитивы – он также может изменять
определения атрибутов или примитивов.
Условия игнорирования
разделов внешнего подмножества DTD
Вы можете
заставить XML-процессор игнорировать часть
внешнего подмножества DTD с помощью раздела
IGNORE. Вы можете,
например, использовать раздел
IGNORE при
разработке документа с целью временного
отключения альтернативного или необязательного
блока объявлений разметки. При этом вам не нужно
удалять строки, а затем повторно их вставлять. (Если
вы программист, то вам известно, что такой прием
подобен "комментированию" фрагмента кода,
который вы хотите временно игнорировать.) Раздел
IGNORE начинается
с символов <![IGNORE[ и
заканчивается символами ]]>.
На рисунке
5.6 представлен пример полного описания внешнего
подмножества DTD, включающего раздел IGNORE.
Рис. 5.6.
Если вы
хотите временно восстановить блок объявлений
разметки в разделе IGNORE, вам достаточно просто
заменить ключевое слово IGNORE на INCLUDE, не
удаляя при этом символы-ограничители (<![, [ и
]]>), как в следующем примере:
<![INCLUDE[
<!-- необязательный блок объявлений разметки,
который временно восстановлен -->
<!ATTLIST BOOK Category CDATA "fiction">
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT AUTHOR (#PCDATA)
]]>
Впоследствии вы можете снова быстро отключить
раздел, вернув заголовок
IGNORE. Раздел
INCLUDE, вложенный в раздел
IGNORE, также
игнорируется.
Примечание. Вы можете
использовать разделы
IGNORE и
INCLUDE только во внешнем
подмножестве DTD, либо во внешнем
параметрическом примитиве. (Внешний
параметрический примитив ссылается на
отдельный файл, который – подобно внешнему
подмножеству DTD – содержит объявления
разметки, подробнее об этом вы узнаете в
лекции 6.)
Преобразование
корректно сформированного документа в валидный
В этом
разделе вы попытаетесь на практике применить
полученные при изучении этой лекции знания,
преобразовав корректно сформированный документ в
валидный. Вы модифицируете документ
Inventory.xml, созданный вами в лекции 2, чтобы
сделать его валидным. Вы также добавите новый
элемент и два атрибута, чтобы освоить описанные
в этой лекции приемы.
Сделаем документ
валидным
- В вашем текстовом
редакторе откройте документ Inventory.xml,
созданный вами в лекции 2.
- Непосредственно
перед элементом Документ – с именем
INVENTORY –
введите следующее объявление типа документа:
<![INCLUDE[
<!-- необязательный блок объявлений разметки,
который временно восстановлен -->
<!ATTLIST BOOK Category CDATA "fiction">
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT AUTHOR (#PCDATA)
]]>
Совет. При выполнении модификации в ходе
данного упражнения вы можете ориентироваться
на полностью модифицированный документ,
который приведен в Листинге 5.1 в конце этой
лекции.
Обратите внимание, что имя следующего за
DOCTYPE
ключевого слова совпадает с именем элемента
Документ, INVENTORY.
DTD состоит только из внутреннего
подмножества, которое определяет элементы и
атрибуты документа следующим образом:
- элемент
Документ,
INVENTORY, имеет содержимое. Он
может включать ни одного или несколько
дочерних элементов BOOK;
- элемент
BOOK также
имеет содержимое. Оно должно включать
строго по одному из следующих элементов,
в порядке, перечисленном в объявлении
документа: TITLE,
AUTHOR,
BINDING,
PAGES и
PRICE;
- элемент
TITLE
имеет смешанное содержимое. Он может
включать символьные данные вместе с ни
одним или с несколькими элементами
SUBTITLE;
- элементы
AUTHOR,
BINDING,
PAGES и
PRICE
также имеют смешанное содержимое. Эти
элементы, однако, могут включать только
символьные данные без дочерних
элементов;
- элемент
BOOK имеет
атрибут нумерованного типа с именем
InStock,
который является обязательным атрибутом
и может принимать значения либо "yes",
либо "no";
- элемент
AUTHOR
имеет атрибут строкового типа с именем
Born,
который является не обязательным и не
имеет значения по умолчанию.
- Добавьте следующий
дочерний элемент
SUBTITLE в элемент
TITLE для
книги Моби-Дик:
<BOOK>
<TITLE>Moby-Dick
<SUBTITLE>Or, the Whale</SUBTITLE>
</TITLE>
- Добавьте
обязательный атрибут
InStock каждому элементу
BOOK, присвоив
ему значения "yes" или "no", как показано
ниже:
<BOOK InStock="yes">
<TITLE>The Adventures of Huckleberry Finn</TITLE>
<AUTHOR>Mark Twain</AUTHOR>
<BINDING>mass market paperback</BINDING>
<PAGES>298</PAGES>
<PRICE>$5.49</PRICE>
</BOOK>
- Добавьте не
обязательный элемент Born к одному или
нескольким элементам. Хотя вы можете
присвоить этому атрибуту любую синтаксически
правильную строку в кавычках, в данном
случае он должен хранить дату рождения
автора. Пример:
<AUTHOR
Born="1835">Mark Twain</AUTHOR>
- Чтобы отразить
новое имя файла, которое вы собираетесь
присвоить, измените комментарий в начале
документа с:
<!-- Имя файла:
Inventory.xml -->
на
<!-- Имя файла:
Inventory Valid.xml -->
- Воспользуйтесь
командой Save As (Сохранить как) вашего
текстового редактора, чтобы сохранить копию
модифицированного документа под именем
Inventory Valid.xml.
Законченный документ представлен в Листинге
5.1.
<?xml
version="1.0"?>
<!-- File Name: Inventory Valid.xml -->
<!DOCTYPE INVENTORY
[
<!ELEMENT INVENTORY (BOOK)*>
<!ELEMENT BOOK (TITLE, AUTHOR, BINDING, PAGES, PRICE)>
<!ATTLIST BOOK InStock (yes|no) #REQUIRED>
<!ELEMENT TITLE (#PCDATA | SUBTITLE)*>
<!ELEMENT SUBTITLE (#PCDATA)>
<!ELEMENT AUTHOR (#PCDATA)>
<!ATTLIST AUTHOR Born CDATA #IMPLIED>
<!ELEMENT BINDING (#PCDATA)>
<!ELEMENT PAGES (#PCDATA)>
<!ELEMENT PRICE (#PCDATA)>
]
>
<INVENTORY>
<BOOK InStock="yes">
<TITLE>The Adventures of Huckleberry
Finn</TITLE>
<AUTHOR Born="1835">Mark Twain</AUTHOR>
<BINDING>mass market paperback</BINDING>
<PAGES>298</PAGES>
<PRICE>$5.49</PRICE>
</BOOK>
<BOOK InStock="no">
<TITLE>Leaves of Grass</TITLE>
<AUTHOR Born="1819">Walt Whitman</AUTHOR>
<BINDING>hardcover</BINDING>
<PAGES>462</PAGES>
<PRICE>$7.75</PRICE>
</BOOK>
<BOOK InStock="yes">
<TITLE>The Legend of Sleepy Hollow</TITLE>
<AUTHOR>Washington Irving</AUTHOR>
<BINDING>mass market paperback</BINDING>
<PAGES>98</PAGES>
<PRICE>$2.95</PRICE>
</BOOK>
<BOOK InStock="yes">
<TITLE>The Marble Faun</TITLE>
<AUTHOR Born="1804">Nathaniel
Hawthorne</AUTHOR>
<BINDING>trade paperback</BINDING>
<PAGES>473</PAGES>
<PRICE>$10.95</PRICE>
</BOOK>
<BOOK InStock="no">
<TITLE>Moby-Dick
<SUBTITLE>Or, the
Whale</SUBTITLE>
</TITLE>
<AUTHOR Born="1819">Herman Melville</AUTHOR>
<BINDING>hardcover</BINDING>
<PAGES>724</PAGES>
<PRICE>$9.95</PRICE>
</BOOK>
<BOOK InStock="yes">
<TITLE>The Portrait of a Lady</TITLE>
<AUTHOR>Henry James</AUTHOR>
<BINDING>mass market paperback</BINDING>
<PAGES>256</PAGES>
<PRICE>$4.95</PRICE>
</BOOK>
<BOOK InStock="yes">
<TITLE>The Scarlet Letter</TITLE>
<AUTHOR>Nathaniel Hawthorne</AUTHOR>
<BINDING>trade paperback</BINDING>
<PAGES>253</PAGES>
<PRICE>$4.25</PRICE>
</BOOK>
<BOOK InStock="no">
<TITLE>The Turn of the Screw</TITLE>
<AUTHOR>Henry James</AUTHOR>
<BINDING>trade paperback</BINDING>
<PAGES>384</PAGES>
<PRICE>$3.35</PRICE>
</BOOK>
</INVENTORY>
Листинг 5.1.
Parts.xml
- Если вы хотите
проверить валидность вашего документа,
воспользуйтесь сценарием проверки XML-документа
на валидность, приведенным в разделе "Проверка
валидности XML-документа" в лекции 9.
|





 Посмотреть
порно видео в онлайне »
Посмотреть
порно видео в онлайне »